
컴퓨터의 기본 구성
하드웨어의 구성
컴퓨터는 중앙처리장치(CPU), 메인메모리, 입력장치, 출력장치, 저장장치로 구성된다.
컴퓨터로 하는 작업의 대부분은 CPU와 메인메모리의 협업으로 이루어지기 때문에 이 두 가지는 필수장치로 분류된다.
그 외의 부품은 주변장치라고 한다.

메인메모리는 전력이 끊기면 데이터를 잃어버리기 때문에 데이터를 영구히 보관하려면 하드디스크나 USB 메모리를 사용해야 한다. 그래서 메인메모리를 제1 저장장치(first storage), 하드디스크나 USB 메모리와 같은 메모리를 제2 저장장치(second stoarge) 또는 보조저장장치라고 부른다. 보통 메인메모리를 '메모리', 보조저장장치를 '저장장치'로 지칭한다.
CPU와 메모리
- CPU: 명령어를 해석하여 실행하는 장치, 두뇌의 역할
- 메모리: 작업에 필요한 프로그램과 데이터를 저장하는 장소. 바이트 단위로 분할되어 있으며 분할 공간마다 주소로 구분한다.
초기의 컴퓨터는 CPU와 메모리뿐이었다.
입출력장치
- 입력장치: 외부의 데이터를 컴퓨터에 입력하는 장치.
- 초기의 컴퓨터 : 천공카드 → 현재의 컴퓨터 : 키보드. 마우스, 스캐너, 터치스크린(스마트폰)
- 출력장치: 컴퓨터에서 처리한 결과를 사용자가 원하는 형태로 출력하는 장치.
- 프린터, 모니터(그래픽카드와 연결), 스피커(사운드카드와 연결)
- 과거: 그래픽 계산을 CPU가 담당하고 그 결과만 그래픽카드에 전달
- 현재: 그래픽용 CPU인 GPU(Graphical Processing Unit)를 그래픽카드에 달아서 직접 계산
- 작은 크기에 많은 컴퓨터 부품을 넣어야 하는 스마트폰은 CPU, GPU, 통신 모듈을 하나의 패키지에 넣어서 사용하는데 이를 AP(Application Processor)라 부른다.
저장장치
- 메모리는 전자의 이동으로 데이터 처리 → 속도가 빠름
- 하드디스크나 CD
- 구동장치가 있는 기계라서 상대적으로 속도가 느림
- 저장 용량에 비해 가격이 저렴하고 데이터를 반영구적으로 저장 가능
- 저장방법
- 자성: 카세트테이프, 플로피디스크, 하드디스크
- 레이저: CD, DVD, 블루레이디스크
- 메모리: USB(Universal Serial Bus) 드라이버, SD(Secure Digital) 카드, CF(Compact Flash) 카드, SSD(Solid State Disk)
메인보드
- CPU와 메모리 등 다양한 부품을 연결하고 전원을 공급해 주는 커다란 판

- 버스(bus)
- 메인보드의 각 장치를 연결하여 데이터가 지나다니는 통로
- 교통수단인 버스가 정해진 경로로 다니듯 메인보드의 버스도 일정한 경로를 따라 각 장치에 데이터를 전송
- 각종 부품(그래픽카드, 사운드카드, 랜카드 등)을 꽂을 수 있는 단자가 마련되어 있기도 하고 단자를 통해 따로 장착되기도 한다.
폰노이만 구조(von Neumann architecture)
- 폰노이만 구조란? 그림과 같이 CPU, 메모리, 입출력장치, 저장장치가 버스로 연결된 구조
오늘날의 컴퓨터는 대부분 폰노이만 구조를 따른다. 폰노이만 구조가 등장하기 전의 컴퓨터는 하드와이어링 형태였기 때문에 다른 용도로 사용하려면 전선의 연결을 바꿔야 했다. 이러한 문제를 해결하고자 미국의 수학자 폰노이만은 메모리를 이용하여 프로그래밍이 가능한 컴퓨터 구조, 즉 하드웨어는 그대로 둔 채 작업을 위한 프로그램만 교체하여 메모리에 올리는 방식을 제안하였다.
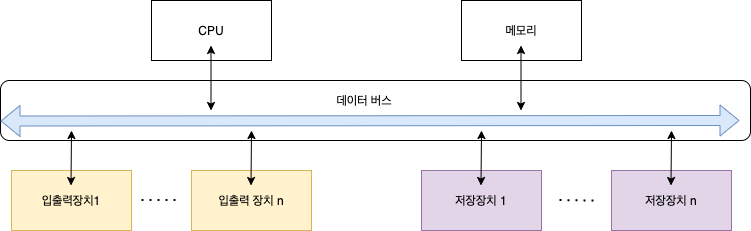
폰노이만 구조
모든 프로그램은 메모리에 올라와야 실행할 수 있다
요리사 모형

- 요리사(CPU)가 요리를 하려면 보관 창고(저장장치)에 있는 재료를 도마(메모리)로 가져와야 한다.
- 주방에서는 도마(메모리)가 핵심적인 작업 공간이고 보관 창고(저장장치)는 보조 공간이다.
- 프로세스 관리: 요리 방법을 결정하는 것은 CPU가 작업을 진행하는 것
- 메모리 관리: 도마 위의 재료를 정리하는 것은 여러 프로그램이 사용하는 메모리를 관리하는 것
- 저장장치 관리: 보관 창고의 재료를 정리하는 것은 저장장치 내의 데이터를 관리하는 것
모든 조건이 동일하다면 메모리가 1GB인 컴퓨터는 메모리가 4GB인 컴퓨터보다 느리다. 이는 요리사의 요리 속도도 중요하지만 도마의 크기(메모리의 크기)도 속도에 영향을 미치는 것과 마찬가지다. 도마가 크면 재료를 모두 가져다 놓고 요리할 수 있지만 도마가 작으면 재료를 모두 가져올 수 없다. 도마의 크기가 전체 재료를 놓을 수 있을 만큼 충분히 크다면 작업 속도에 영향을 미치지 않는다. 예를 들어 메모리가 20GB인 컴퓨터와 40GB인 컴퓨터의 작업 속도는 크게 차이가 나지 않는다. 재료보다 도마의 크기가 작을 때만 문제되는 것이다.
보관 창고(저장장치)의 크기도 작업 속도에 영향을 미치지 않는다.
기초 용어 정리
크기 단위
- Byte(2⁰, 1), KB(2¹⁰, 10³), MB(2²⁰, 10⁶), GB(2³⁰, 10⁹), TB(2⁴⁰, 10¹²), PB(2⁵⁰, 10¹⁵)
클록과 헤르츠
- 클록(clock) - tick
- 컴퓨터에서 일정한 박자를 만들어 내는 것
- 클록에 의해 일정 간격으로 만들어지는 틱(tick)을 펄스(pulse) 혹은 클록 틱(clock tick)이라 부른다.
- 클록이 일정 간격으로 펄스를 만들면 거기에 맞추어 컴퓨터 안의 모든 구성 부품들이 작업을 진행한다.
- CPU가 여러 번 덧셈을 하는 경우 클록(혹은 클록 틱) 한 번에 한 번의 덧셈이 이뤄진다.
- 메모리에서 데이터를 가져오거나 저장할 때도 클록이 발생할 때마다 데이터를 저장 또는 가져온다.
- 헤르츠(Hertz) - Hz
- 시간에 따라 변화가 일어날 때 사용하는 단위
- 1초 동안 몇 번의 작업이 이루어져서 몇 번의 펄스(클록 틱)이 발생하였는가를 의미
- 1초에 펄스가 1번 → 1Hz, 1000번 → 1KHz
- 예시
- 3GHz의 CPU → 1초 동안 약 3 x 10⁹ 번(약 30억 번)의 작업이 가능한 CPU
- 속도가 1.6GHz인 메모리 → 1초에 1.6 x 10⁹의 속도로 데이터를 저장할 수 있는 메모리
시스템 버스와 CPU 버스
- 시스템 버스(system bus)
- 메모리와 주변장치를 연결하는 버스, 메인보드의 동작 속도를 의미
- FSB(Front-Side Bus) 또는 전면 버스라고 부름
- FSB 3,200MHz(3.2GHz)는 메인보드의 버스 클록이 최대 3,200MHz라는 의미 → 메모리도 3,200MHz의 속도로 작동
- CPU 내부 버스(BSB; Back Side Bus)
- CPU 내부에도 다양한 장치들이 있는데 이들은 CPU 내부 버스로 연결된다.
- CPU 내부에 있는 장치를 연결하는 버스를 BSB(Back Side Bus) 또는 후면 버스라고 부른다.
프로그래밍 언어
- 프로그램(program): 컴퓨터에 알려줄 작업을 하나로 모은 것
- 기계어(machine language)
- 컴퓨터가 이해할 수 있는 유일한 언어
- 0과 1의 이진수로 구성
- 어셈블리어(assembly language)
- 기계어를 사람들이 이해할 수 있는 문자 형태로 바꾼 언어
- 0과 1의 이진수를 문자 형태로 바꿔놓았을 뿐이므로 전문가만 사용 가능
- 기계어에 가깝지만 일반인이 사용하기엔 어려운 프로그래밍 언어를 저급언어(low level language)라 부름
- 고급언어
- if나 for 같이 일반인이 이해할 수 있는 단어를 사용하여 만든 언어를 고급언어(high level language)라 부름
- 기계어와 어셈블리어를 제외한 대부분의 언어가 고급언어
- 컴퓨터는 기계어만을 인식
→ 고급언어(ex. C)를 사용하여 만든 소스코드 이해 불가
→ 소스코드를 기계어로 번역하는 작업 필요
- 컴파일(compile)
- 고급언어를 기계어로 변역하는 과정
- 컴파일러(compiler)
- 컴파일을 담당하는 프로그램
- 컴파일러는 소스코드를 번역하여 기계어로 이루어진 실행 파일을 만듦
- 컴퓨터는 이 실행 파일을 실행함으로써 작업을 시작
- 컴파일 방식을 사용
- 실행 파일을 만들기 전에 오류를 찾음
- 필요 없는 변수들을 삭제
- 반복되는 작업을 하나로 합침
- C, C++, Java와 같은 대부분의 고급언어가 컴파일 방식을 사용
- 인터프리터(interpreter)
- 소스코드를 기계어로 번역하는 다른 방법
- 소스코드를 한 번에 한 문장씩 번역하여 실행
- 대표적인 인터프리터 언어: 자바스크립트(Javascript)
- 장점: 컴파일러와 달리 실행 파일을 따로 만들지 않음
- 단점
- 위부터 한 줄씩 실행되기 때문에 코드에 잘못된 부분이 있는지 파악하기 어려움
- 반복되는 작업을 하나로 합치기 힘듦
CPU와 메모리
CPU의 구성과 동작
CPU의 기본 구성
- CPU는 명령어를 해석하여 실행하는 장치, 요리사 모형에서 요리사에 해당
- CPU는 산술논리 연산장치, 제어장치, 레지스터로 구성 → 이것들의 협업으로 작업을 처리한다.
- 산술논리 연산장치(ALU; Arithmetic and Logic Unit)
- 요리사가 재료를 삶거나 찌거나 볶는 행위
- 데이터를 연산하는 장치
- 데이터의 덧셈, 뺄셈, 곱셈, 나눗셈 같은 산술 연산과 AND, OR 같은 논리 연산 수행
- 제어장치(control unit)
- 요리사가 보조 요리사나 주방 보조에게 작업 지시
- CPU에서 작업을 지시하는 부분
- 레지스터(register)
- 요리 중간에 재료를 손질하기보다 필요한 재료를 미리 손질해 놓으면 요리하기 편함
- 작업에 필요한 데이터를 CPU 내부에 보관하는 곳이 레지스터
- 역할
- 레지스터는 계산을 하기 위해 가져온 데이터를 저장
- 계산의 중간 값을 임시로 보관
- 작업을 진행하기 위해 필요한 정보를 보관
CPU의 명령어 처리 과정
[예시] 변수 D2에 저장된 값 2와 D3에 저장된 값 3을 더하여 그 결과 값인 5를 sum에 저장하는 pseudo code
int D2 = 3; //메모리 100번지가 D2라고 가정
int D3 = 3; //메모리 120번지가 D3라고 가정
int sum; //메모리 160번지가 sum이라고 가정
sum = D2 + D3;프로그래밍 언어에서 변수를 선언 → 메모리 내에 작업 공간을 만듦
- 메모리의 작업 공간은 107번지, 128번지와 같이 주소로 접근
→ 외우기 어렵다
→ 주소 대신 D2, D3, sum과 같이 메모리 주소의 '다른 이름'을 붙여줌
CPU는 0과 1의 2진수로 이뤄진 기계어만 인식한다.
위 코드를 실행하려면 컴파일러를 이용하여 기계어로 바꿔야 한다.
[어셈블리어 pseudo code]
LOAD mem(100), register 2 //메모리 100번지(D2) 내용을 R2로 이동
LOAD mem(120), register 3 //메모리 120번지(D3) 내용을 R3로 이동
ADD register 5, register 2, register 3 //R2와 R3를 더한 후 R5에 임시저장
MOVE register 5, mem(160) //R5 결과를 160번지(sum)에 저장
[CPU의 명령어 처리 과정]
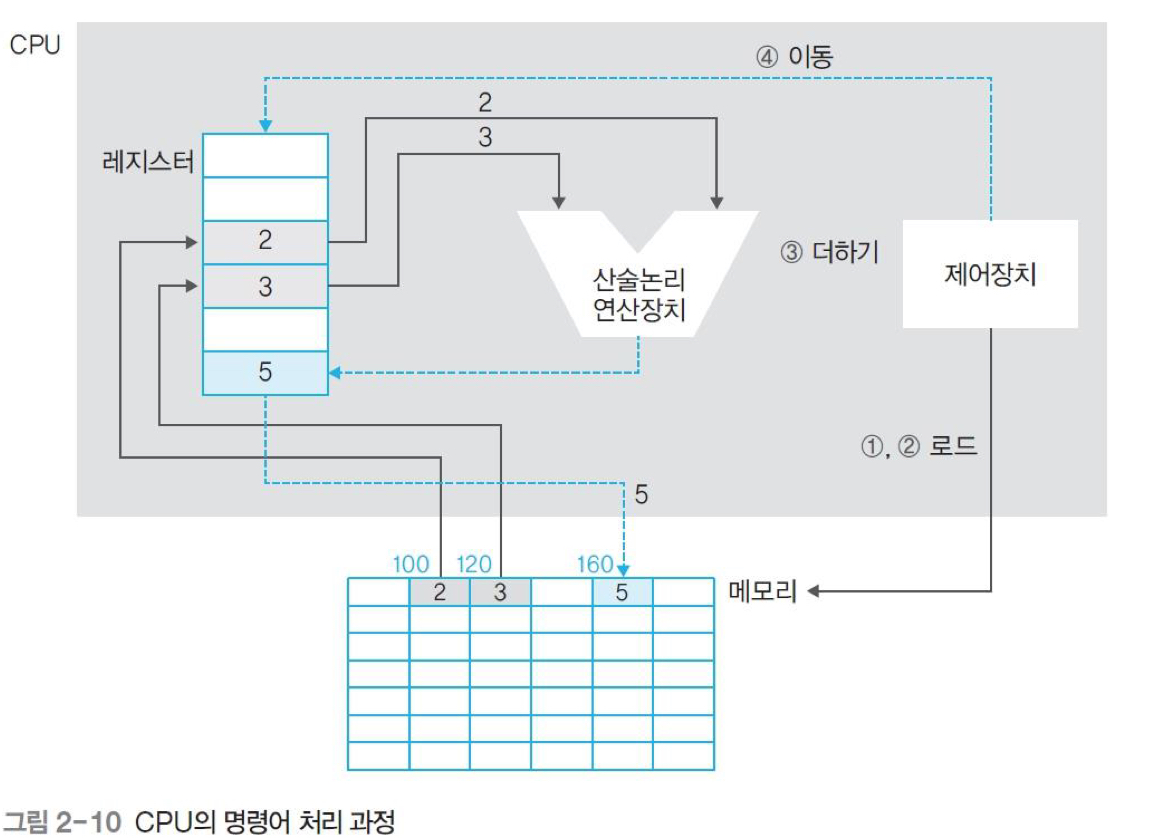
레지스터의 종류
CPU는 필요한 데이터를 메모리에서 가져와 레지스터에 저장하고 산술논리 연산장치를 이용하여 연산한 후, 그 결과를 다시 레지스터에 저장했다가 메모리로 옮긴다.이때 사용되는 레지스터는 데이터 레지스터와 주소 레지스터로 이들은 사용자 프로그램에 의해 변경되기 때문에 사용자 가시 레지스터(user-visible register)라고 부른다.
사용자 가시 레지스터
- 데이터 레지스터(DR; data register)
- 메모리에서 가져온 데이터를 임시로 보관할 때 사용
- CPU에 있는 대부분의 레지스터가 데이터 레지스터이기 때문에 일반 레지스터 또는 범용 레지스터라고 부름
- 주소 레지스터(AR; address register)
- 데이터 또는 명령어가 저장된 메모리의 주소는 주소 레지스터에 저장됨
특별한 용도로 사용되는 레지스터를 특수 레지스터라고 한다. 특수 레지스터는 사용자가 임의로 변경할 수 없기 때문에 사용자 불가시 레지스터(user-invisible register)라고 부른다. 특수 레지스터에는 다음과 같은 종류가 있다.
사용자 불가시 레지스터(특수 레지스터)
- 프로그램 카운터(PC; program counter)
- CPU는 다음에 어떤 명령어를 처리해야 할지 알아야 함
- 프로그램 카운터는 다음에 실행할 명령어의 주소를 기억하고 있다가 제어장치에 알려줌
- 다음에 실행할 명령어의 주소를 기리키기 때문에 프로그램 카운터를 명령어 포인터라고도 함
- 명령어 레지스터(IR; instruction register)
- 현재 실행 중인 명령어 저장
- 제어장치는 명령어 레지스터에 있는 명령을 해석한 후 외부 장치에 적절한 제어 신호를 보냄
- 메모리 주소 레지스터(MAR; memory address register)
- 메모리에서 데이터를 가져오거나 반대로 메모리로 데이터를 보낼 때 주소를 지정하는 데 사용
- 명령어 처리 과정에서 필요한 메모리 주소를 이 레지스터에 넣으면 메모리 관리자가 인식하여 해당 메모리 위치의 데이터를 가져오거나 해당 메모리 위치에 데이터를 저장
- 메모리 버퍼 레지스터(MBR; memory buffer register)
- 메모리에서 가져온 데이터나 메모리로 옮겨갈 데이터를 임시로 저장
- 메모리 버퍼 레지스터는 항상 메모리 주소 레지스터와 함께 동작
[LOAD mem(100), register 2가 처리되는 과정]

- 프로그램 상태 레지스터(PSR; Program Status Register)
- 조건의 결과에 따라 다른 코드가 실행되는 if와 같은 분기(branch) 문장에 이용됨
- 프로그램 상태 레지스터는 산술논리 연산장치(ALU)와 연결, 연산 결과를 저장
- 플래그 레지스터(flag register), 상태 레지스터(status register), 컨디션 레지스터(condition register)라고도 부름
[분기 조건이 있는 코드]
if (D2 - D3 > 0)
goto 100;
else
goto 200;
버스의 종류
CPU와 메모리, 주변장치 간에 데이터를 주고받을 때는 시스템 버스를 사용한다. 시스템 버스는 제어 버스, 주소 버스, 데이터 버스로 나뉜다. 시스템 버스에는 작업을 지시하는 제어 신호, 메모리의 위치 정보를 알려주는 주소, 여러 종류의 데이터가 오고 간다.
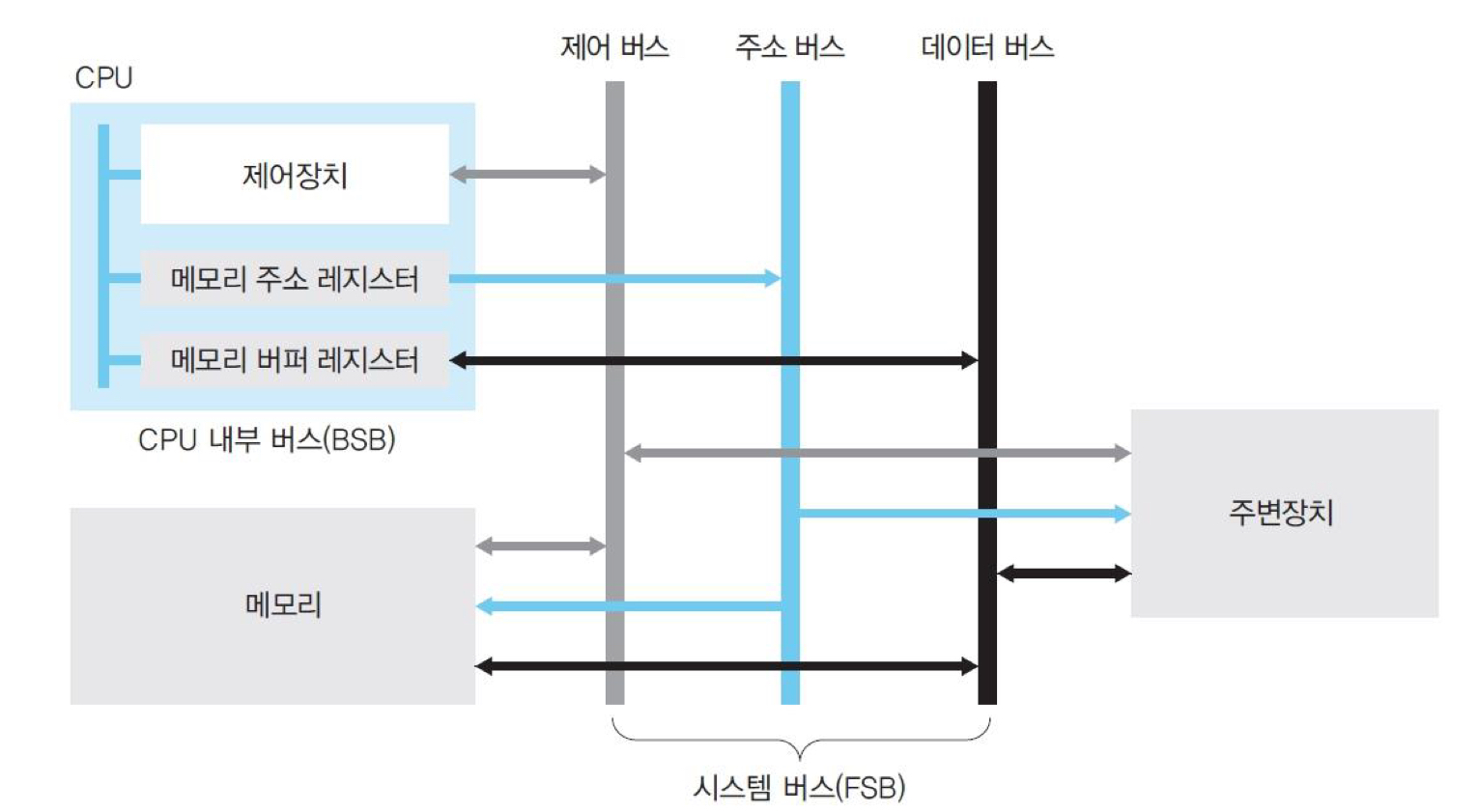
- 제어 버스(control bus)
- 다음에 어떤 작업을 할지 지시하는 제어 신호가 오고 감
- 메모리에서 데이터를 가져올 때는 읽기 신호를 보내고 처리한 데이터를 메모리로 옮겨 놓을 때는 쓰기 신호를 보냄
- 하드디스크에 저장 명령을 내리거나 사운드카드에 소리를 내라는 명령을 내릴 때 제어 버스를 통해 전달
- 제어 버스는 CPU의 제어장치와 연결됨
→ 메모리에서 오류가 발생하거나 네트워크 카드에 데이터가 모두 도착했다는 신호는 모두 제어 버스를 통해 CPU로 전달됨 - 제어 버스의 신호는 CPU, 메모리, 주변장치와 양방향으로 오고 감
- 주소 버스(address bus)
- 메모리의 데이터를 읽거나 쓸 때 어느 위치에서 작업할 것인지를 알려주는 위치 정보(주소)가 오고 감
- 하드디스크의 어느 위치에서 데이터를 읽어올지, 어느 위치에 저장할지에 대한 위치 정보가 주소 버스를 통해 전달됨
- 메모리 주소 레지스터와 단방향으로 연결됨
- CPU에서 메모리나 주변장치로 나가는 주소 정보는 있지만 주소 버스를 통해 CPU로 전달되는 정보는 없음
- 데이터 버스(data bus)
- 제어 버스가 다음에 어떤 작업을 할지 신호를 보내고 주소 버스가 위치 정보를 전달하면 데이터가 데이터 버스(data bus)에 실려 목적지까지 이동
- 메모리 버퍼 레지스터와 양방향으로 연결됨
CPU 비트의 의미
- 버스의 대역폭(bandwidth): CPU가 한 번에 처리할 수 있는 데이터의 최대 크기
- ex) 32bit CPU - 메모리에서 데이터를 읽거나 쓸 때 한 번에 최대 32bit를 처리할 수 있으며 이 경우 레지스터의 크기도 32bit, 버스의 대역폭도 32bit이다.
- 워드(word): CPU가 한 번에 처리할 수 있는 데이터의 최대 크기
- ex) 32bit CPU에서 1워드 - 32bit
- ex) 64bit CPU에서 1워드 - 64bit
메모리의 종류와 부팅
메모리의 종류
메모리는 읽거나 쓸 수 있는 램(RAM; Random Access Memory)과 읽기만 가능한 롬(ROM; Read Only Memory)으로 구분
램은 무작위로 데이터를 읽어도 저장된 위치와 상관없이 같은 속도로 데이터를 읽을 수 있다는 의미에서 붙은 이름
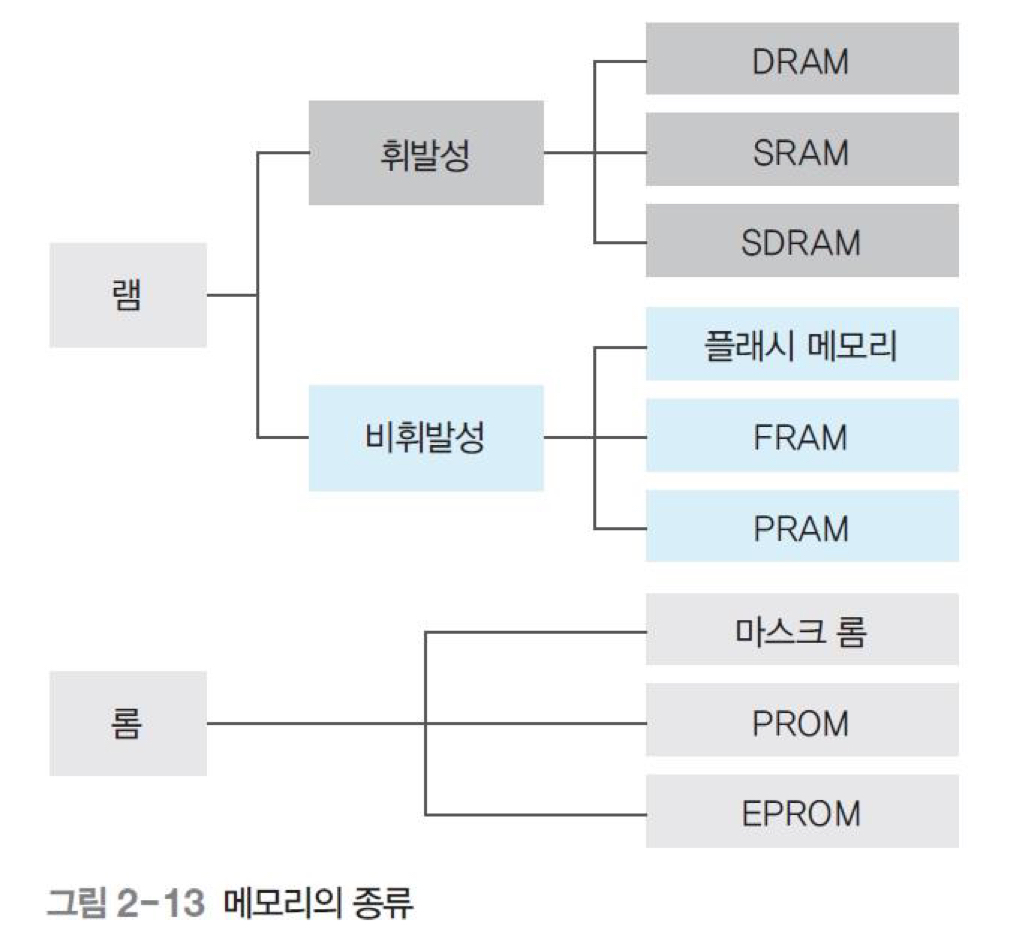
램은 전력이 끊기면 데이터가 사라지는 휘발성 메모리와 전력이 끊겨도 데이터를 보관할 수 있는 비휘발성 메모리로 나뉜다.
- 휘발성 메모리(volatility memory)
- 종류: DRAM(Dynamic RAM, 동적 램), SRAM(Static RAM, 정적 램)
- DRAM
- 저장된 0과 1의 데이터가 일정 시간이 지나면 사라지므로 일정 시간마다 다시 재생시켜야 함
- DRAM의 Dynamic은 시간이 지나면 데이터가 사라지기 때문에 재생이 필요하다는 의미
- SRAM
- 전력이 공급되는 동안에는 데이터를 보관할 수 있어 재생할 필요가 없다.
- 속도는 빠르지만 가격이 비싸다.
- 일반적으로 메인메모리에는 DRAM, 캐시 같은 고속 메모리에는 SRAM 사용
- 메인메모리를 비휘발성 메모리로 만들면 전력이 끊겨도 내용이 남기 때문에 편리할 수 있다. 하지만 전력이 끊겨도 데이터를 보관하기 위해 메모리 내부가 복잡하고 속도가 느리며 가격이 비싸다. 그래서 아직까지도 메인메모리는 휘발성 메모리를 사용하고 있다.
- 비휘발성 메모리(non-volatility memory)
- 종류: 플래시 메모리(flash memory), FRAM(Ferroelectric RAM), PRAM(Phase change RAM)
- 플레시 메모리: 전력이 없어도 데이터를 보관하는 저장장치로 많이 사용됨.
- 예시) 디지털카메라, MP3 플레이어, USB 드라이버
- 플래시 메모리의 각 소자는 최대 사용 횟수가 제한되어 있어 보통 소자 하나당 몇 천 번에서 만 번 정도 사용하면 제 기능을 잃는다 → SD 카드나 USB 드라이버를 오래 사용하면 성능이 저하되거나 데이터를 잃어버릴 수 있으니 주의
- SSD
- 하드디스크를 대신할 수 있는 비휘발성 메모리
- 장점: 빠른 데이터 접근 속도, 저전력, 높은 내구성
- 단점: 비싼 가격
- 개인용 컴퓨터, 노트북, 스마트폰 등 많은 기기에 사용됨
- 롬(ROM)
- 램과 달리 롬은 전력이 끊겨도 데이터를 보관할 수 있다는 것이 장점이지만 데이터를 한 번 저장하면 바꿀 수 없다. 이러한 특성 때문에 바이오스(BIOS; Basic Input/Output System)를 롬에 저장한다.
- 종류: 데이터를 지우거나 쓸 수 없는 마스크 롬(mask ROM), 전용 기계를 이용하여 데이터를 한 번만 저장할 수 있는 PROM(Programmable ROM), 데이터를 여러 번 쓰고 지울 수 있는 EPROM(Erasable Programmable ROM)이 있다. EPROM은 플래시 메모리처럼 사용할 수 있지만 가격이 비싸 잘 사용하지 않는다.
메모리 보호
일괄 작업 시스템(일괄 처리 시스템)에서는 메모리가 운영체제 영역과 사용자 영역으로 구분된다. 이 시스템에서 메모리 보호는 사용자 영역의 작업이 운영체제 영역으로 침범하지 못하도록 막는 것이다. 현대의 운영체제는 시분할 기법을 사용하여 여러 프로그램을 동시에 실행하므로 사용자 영역이 여러 개의 작업 공간으로 나뉘어 있다. 이러한 상황에 메모리가 보호되지 않는다면 어떤 작업이 다른 작업의 영역을 침범하여 프로그램을 파괴하거나 데이터를 지울 수도 있으며, 최악의 경우 운영체제 영역을 침범하여 시스템이 멈출 수도 있다. 이처럼 운영체제 영역이나 다른 프로그램 영역으로 침범하려는 악성 소프트웨어를 바이러스라고 한다.
운영체제도 CPU를 사용하는 작업 중 하나이기 때문에 사용자 프로세스가 CPU를 차지하여 작업이 진행되는 동안에는 운영체제 작업이 잠시 중단된다. 운영체제 작업이 중단된 상태에서 사용자 작업으로부터 메모리를 보호하려면 하드웨어의 도움이 필요하다.
메모리를 보호하기 위해 CPU는 현재 진행 중인 작업의 메모리 시작 주소를 경계 레지스터(bound register)에 저장한 후 작업한다. 그리고 현재 진행 중인 작업이 차지하고 있는 메모리의 크기, 즉 마지막 주소까지의 차이를 한계 레지스터(limit register)에 저장한다. 사용자 작업이 진행되는 동안 이 두 레지스터의 주소 범위를 벗어나는지 하드웨어 측면에서 점검함으로써 메모리를 보호한다.
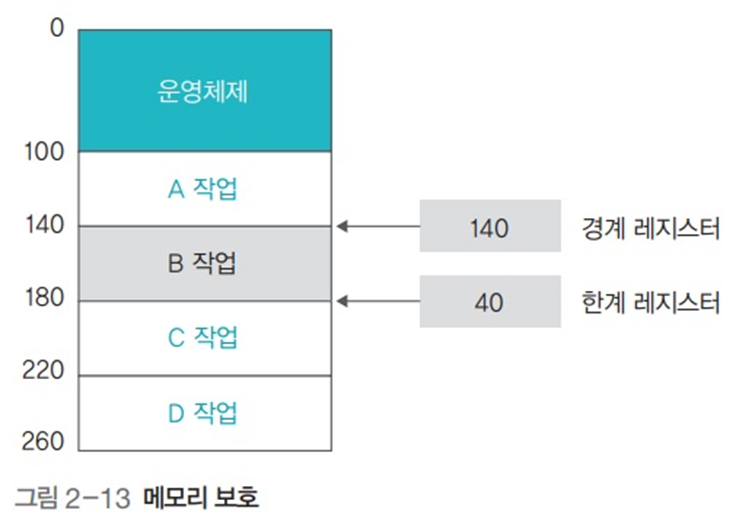
- B 작업의 메모리 시작 주소 140은 경계 레지스터, 크기 40은 한계 레지스터에 저장됨
- B 작업이 데이터를 읽거나 쓸 때마다 CPU는 해당 작업이 경계 레지스터와 한계 레지스터의 주소 값 안에서 이루어지는지 검사
- 두 레지스터의 값을 벗어난다면 메모리 오류와 관련된 신호가 발생
- 이 신호를 인터럽트라 부름, 신호가 발생하면 모든 작업이 중단되고 CPU는 운영체제를 깨워 문제를 처리하도록 시킴
- 메모리 영역을 벗어나 발생한 신호(인터럽트)의 경우에는 운영체제가 해당 프로그램을 강제 종료시킴
이처럼 모든 메모리 영역은 하드웨어와 운영체제의 협업에 의해 보호받는다.
부팅(booting)
- 컴퓨터를 켰을 때 운영체제를 메모리에 올리는 과정
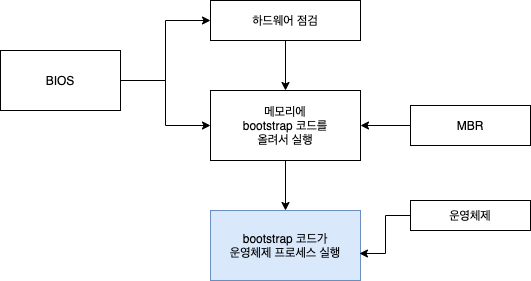
- 사용자가 컴퓨터의 전원을 켜면 롬에 저장된 바이오스(BIOS; Basic Input/Output System)가 실행
- 바이오스는 CPU, 메모리, 하드디스크, 키보드, 마우스와 같은 주요 하드웨어가 제대로 작동하는지 확인, 이상이 있으면 '삐~' 소리와 함께 오류 메시지 출력
- 하드웨어 점검 완료 시 바이오스의 맨 마지막 작업은 하드디스크의 마스터 부트 레코드(MBR; Master Boot Record)에 저장된 작은 프로그램을 메모리로 가져와 실행한다.
- 마스터 부트 레코드는 하드디스크의 첫 번째 섹터를 가리키며 운영체제를 실행하기 위한 코드인 부트스트랩(bootstrap)이 저장되어 있다.
- 부트스트랩 코드(로더 loader): 하드디스크에 저장된 운영체제를 메모리로 가져와 실행하는 역할을 하는 작은 프로그램
- 예시) 유닉스용 부트스트랩 코드가 실행되면 유닉스 운영체제가 메모리에 올라오고 윈도우용 부트스트랩 코드가 실행되면 윈도우 운영체제가 메모리에 올라온다.
- 한 컴퓨터에 운영체제 2개를 설치해 보면 부트스트랩을 확인할 수 있다(1개만 설치 시 바로 운영체제를 메모리에 올린다).
- 부트스트랩 코드(로더 loader): 하드디스크에 저장된 운영체제를 메모리로 가져와 실행하는 역할을 하는 작은 프로그램
컴퓨터 성능 향상 기술
현대 컴퓨터 구조의 가장 큰 문제는 CPU와 메모리, 주변장치의 작업 속도가 다르다는 것이다. 메인보드 내 메모리와 주변장치는 시스템 버스(FSB)로 연결되어 있고, CPU 내 레지스터, 산술 논리 연산장치, 제어장치는 CPU 내부 버스(BSB)로 연결되어 있다. 따라서 메모리 속도는 시스템 버스의 속도와 같고 CPU 속도는 CPU 내부 버스의 속도와 같다. 그런데 CPU 내부 버스의 속도가 시스템 버스의 속도보다 빠르기 때문에 메모리를 비롯한 주변장치의 속도가 CPU 속도를 따라가지 못한다. CPU에 비하면 메모리가 느리고 프로그램과 데이터를 보관하는 하드디스크의 속도는 더욱 느리다. 이런 장치 간 속도 차이를 개선하고 시스템의 작업 속도를 올리기 위해 개발된 기술을 살펴보자.
버퍼(Buffer)
개념
- 두 장치 사이의 속도 차이를 완화하는 역할
- 입출력장치에서 데이터를 가져올 때 데이터를 모아 한꺼번에 전송하면 작은 작업량으로도 많은 양의 데이터를 옮길 수 있다.
- 이처럼 일정량의 데이터를 모아서 옮겨 속도 차이를 완화하는 장치가 버퍼
- 하드디스크에는 메모리 버퍼가 존재. 같은 사양의 하드디스크라면 버퍼 용량이 큰 것이 더 빠르다.
- ex) 1TB, 7200rpm, 256MB(하드디스크 용량, 디스크 회전 속도, 버퍼 용량)
- 버퍼가 소프트웨어에서 사용되는 대표적인 예는 동영상 스트리밍 - 유튜브에서 동영상을 볼 때 네트워크에서 데이터가 들어오는 시간과 플레이어가 재생하는 시간의 속도 차이가 발생하기도 한다. 플레이어가 재생되는 도중에 데이터가 도착하지 않으면 동영상이 끊기는데, 이러한 현상을 방지하기 위해 동영상 데이터의 일정 부분을 버퍼에 넣은 후 실행한다.
모니터 버퍼
모니터도 버퍼를 사용한다. 프로그램에서 처리한 결과를 화면에 출력할 때 한 줄이 다 차지 않으면 출력이 안되는 경우가 있다. C 언어의 출력문인 printf("Hello \n");에서 \n은 줄 바꿈의 의미도 있지만 버퍼에 저장된 내용을 출력하라는 의미도 있다. 따라서 printf를 사용할 때 마지막에 \n을 붙이는 습관을 들이는 것이 좋다.
스풀(SPOOL; Simultaneous Peripheral Operation On-Line)
- 스풀은 CPU와 입출력장치가 독립적으로 동작하도록 고안된 소프트웨어적인 버퍼
- 대표적인 예시) 프린터에서 사용되는 스풀러(spooler)
- 인쇄할 내용을 순차적으로 출력하는 소프트웨어
- 출력 명령을 내린 프로그램과 독립적으로 작동
[워드프로세서로 작업하고 프린터로 출력하는 경우]
- 스풀러가 없다면 모든 출력을 워드프로세서가 알아서 처리해야 함 → 인쇄가 끝날 때까지 워드프로세서를 사용할 수 없음
- 스풀러 사용 시 인쇄할 내용을 하드디스크의 스풀러 공간에 저장하고 워드 프로세서는 다른 작업을 할 수 있음
- 문서 작업과 프린트 출력 작업이 독립적으로 진행되는 것
스풀러는 버퍼의 일종이지만 다른 점
- 프로그램이 버퍼를 공유하기 때문에 어떤 프로그램의 데이터이든 버퍼가 다 차면 이동이 시작
- 반면에 스풀러는 한 인쇄물이 완료될 때까지 다른 인쇄물이 끼어들 수 없으므로 프로그램 간에 배타적
하드웨어 안전 제거
버퍼를 사용하면 버퍼가 다 채워질 때까지 저장장치 간의 데이터 전송이 지연된다.
따라서 외부 저장장치에 데이터를 복사 후 바로 제거하면 안된다. 컴퓨터의 종료 버튼을 누르지 않고 전원 코드를 뽑는 경우도 마찬가지다. 갑작스러운 전원의 변화로 부품이 망가지기도 하고 버퍼가 차지 않아 공들여 작업한 내용이 사라질 수 있다.
이때 '하드웨어 안전 제거' 기능 이용 시 버퍼가 저장장치에 반영되지 않는 문제를 해결할 수 있다. 이 기능은 버퍼에 있는 아직 ㅇ롬겨지지 않은 데이터를 USB 등의 저장장치로 보내고 USB의 전원을 차단하여 안전하게 제거할 수 있도록 준비해 준다. 유닉스에서는 버퍼의 내용을 강제로 전송하는 명령어로 fflush를 사용한다.
캐시(cache)
캐시는 메모리와 CPU 간의 속도 차이를 완화하기 위해 메모리의 데이터를 미리 가져와 저장해 두는 임시 장소다. 캐시는 필요한 데이터를 모아 한꺼번에 전달하는 버퍼의 일종으로 CPU가 앞으로 사용할 것으로 예상되는 데이터를 미리 가져다 놓는다. 이렇게 미리 가져오는 작업을 'prefetch'라고 한다.
요리를 하다가 간장 10cc가 필요한 경우를 생각하면 장독대에 가서 간장을 10cc만 가져오면 다음에 간장이 필요할 때 또 장독대에 가야 한다. 하지만 50cc를 가져다 놓으면 다음에 간장이 필요할 때 시간을 단축할 수 있다. 이처럼 필요하다고 생각되는 일정량의 데이터를 미리 가져와 저장해 두는 곳이 캐시다.
CPU 안에 있는 캐시는 CPU 내부 버스의 속도로 작동한다. 메모리는 시스템 버스의 속도로 작동하기 때문에 느리다. 캐시는 빠른 속도로 작동하는 CPU와 느린 속도로 작동하는 메모리 사이에서 두 장치의 속도 차이를 완화해 준다.
캐시는 메모리의 내용 중 일부를 미리 가져오고 CPU는 메모리에 접근할 때 먼저 캐시를 방문하여 원하는 데이터가 있는지 찾아본다. 캐시에서 원하는 데이터를 찾았을 때 캐시 히트(cache hit)라고 하며 그 데이터를 바로 사용한다. 그러나 원하는 데이터가 캐시에 없으면 메모리로 가서 데이터를 찾는다. 이를 캐시 미스(cache miss)라고 한다. 캐시 히트가 되는 비율을 캐시 적중률(cache hit ratio)이라고 하며 일반적인 컴퓨터의 캐시 적중률은 약 90%이다.

컴퓨터의 성능을 향상하려면 캐시 적중률이 높아야 한다.
캐시 적중률을 높이는 방법
- 캐시 적중률을 높이는 방법 중 하나는 캐시의 크기를 늘리는 것이다. 캐시의 크기가 커지면 더 많은 데이터를 미리 가져올 수 있어 캐시 적중률이 올라간다. 클록이 같은 CPU라도 저가형과 고가형은 캐시의 크기가 다르다. 예를 들면 저가의 인텔 i7은 캐시 메모리가 4MB이지만 고가의 i7은 8MB 이상이다. 캐시는 가격이 비싸기 때문에 크기를 늘리는 데 한계가 있어 몇 메가바이트 정도만 사용한다.
- 캐시 적중률을 높이는 또 다른 방법은 데이터를 가져오는 것이다. 이와 관련된 이론으로는 현재 위치에 가까운 데이터가 멀리 있는 데이터보다 사용될 확률이 더 높다는 지역성(locality) 이론이 있다. 예컨대 현재 프로그램의 10행이 실행되고 있다면 다음에 11행이 실행될 확류이 101행이 실행될 확률보다 더 높다. 따라서 현재 10행을 실행하는 경우 지역성 이론에 따라 11~20행을 미리 가져오면 된다.
프로그래밍 시 goto 문을 사용하면 다음 행이 실행될 것으로 예상하여 캐시에 미리 저장된 데이터가 쓸모없어진다.
캐시에 있는 데이터가 변경되면 이를 반영해야 하는 문제도 있다. 캐시는 메모리에 있는 데이터를 임시로 가져온 것이기 때문에 캐시에 있는 데이터가 변경되면 메모리에 있는 원래 데이터를 변경해야 한다. 캐시의 변경된 데이터를 메모리에 반영하는 데에는 즉시 쓰기 방식과 지연 쓰기 방식이 있다.
- 즉시 쓰기(write through)
- 캐시에 있는 데이터가 변경되면 이를 즉시 메모리에 반영하는 방식
- 메모리와의 빈번한 데이터 전송으로 성능이 느려진다는 것이 단점
- 하지만 메모리의 최신값이 항상 유지되기 때문에 급작스러운 정전에도 데이터를 잃어버리지 않는다.
- 지연 쓰기(write back)
- 캐시에 있는 데이터가 변경되면 그 내용을 모아서 주기적으로 반영하는 방식으로 카피백(copy back)이라고도 함
- 메모리와의 데이터 전송 횟수가 줄어들어 시스템 성능을 향상할 수는 있음
- 메모리와 캐시된 데이터 사이의 불일치가 발생할 수도 있다는 것이 단점
프로그램의 명령어는 크게 어떤 작업을 할지 나타내는 명령어 부분과 작업 대상인 데이터 부분으로 나눌 수 있다.
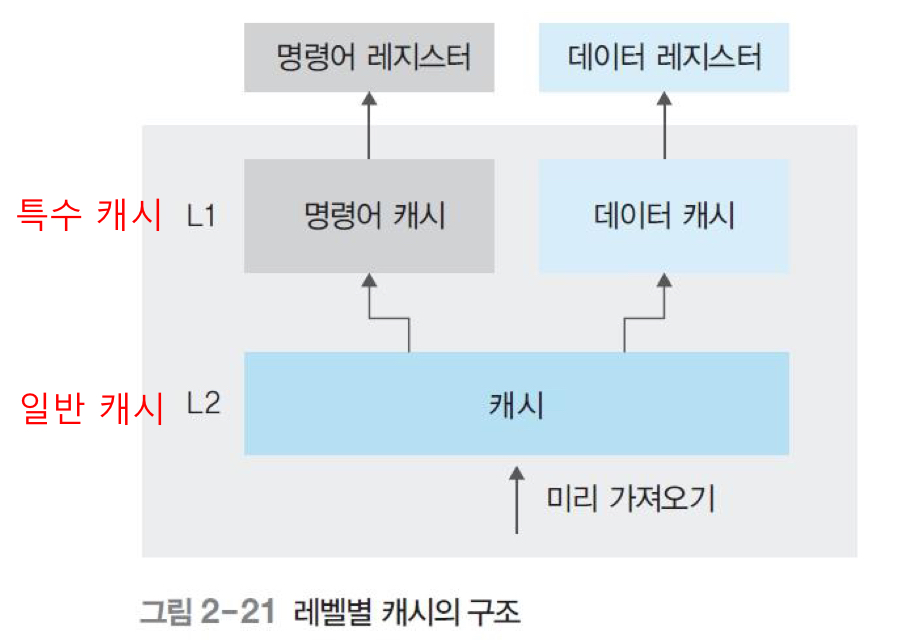
- 캐시의 두 가지 레벨
- 명령어와 데이터의 구분 없이 모든 자료를 가져오는 일반 캐시
- 명령어와 데이터를 구분하여 가져오는 특수 캐시
아래 그림은 레벨별 캐시의 구조를 나타낸다. 명령어 캐시는 명령어 레지스터와 연결되어 있고, 데이터 캐시는 데이터 레지스터와 연결되어 있다. 명령어 캐시나 데이터 캐시는 CPU 레지스터에 직접 연결되기 때문에 L1(level 1) 캐시라 부르고 일반 캐시는 메모리와 연결되기 때문에 L2(level 2) 캐시라 부른다.
웹 브라우저 캐시
캐시가 소프트웨어적으로 사용되는 대표적인 예시 → 웹 브라우저 캐시
웹에서 사용하는 캐시는 '앞으로 다시 방문할 것을 예상하여 지우지 않은 데이터'로 정의할 수 있다. 네이버와 같이 자주 방문하는 사이트의 경우 로고나 버튼처럼 자주 바뀌지 않는 작은 그림은 데이터를 캐시에 보관하고 있다가 사이트를 다시 방문하면 캐시에 있는 그림 데이터를 사용하여 속도를 높인다. 이처럼 웹 브라우저의 캐시는 방문했던 사이트의 데이터를 보관하여 재방문 시 속도를 높이는 역할을 한다. 그러나 너무 많은 데이터가 캐시에 보관되어 있으면 웹 브라우저 속도를 떨어뜨릴 수 있으므로 가끔 정리를 하는 것이 좋다.
저장장치의 계층 구조
- 높은 성능의 컴퓨터를 구성하는 방법
- 느린 하드디스크 대신 SSD와 같은 빠른 플래시 메모리를 저장장치로 사용
- 메모리를 하드디스크 크기만큼 확장
- 캐시를 크게 늘려 캐시 적중률을 높임
→ 위의 방법들은 비용이 많이 듦
→ 가격과 컴퓨터 성능 사이의 타협점으로 저장장치의 계층 구조(storage hierarchy)가 존재
- 저장장치의 계층 구조
- 속도가 빠르고 값이 비싼 저장장치를 CPU 가까운 쪽 배치
- 값이 싸고 용량이 큰 저장장치를 반대쪽에 배치
- 적당한 가격으로 빠른 속도와 큰 용량을 동시에 얻는 방법
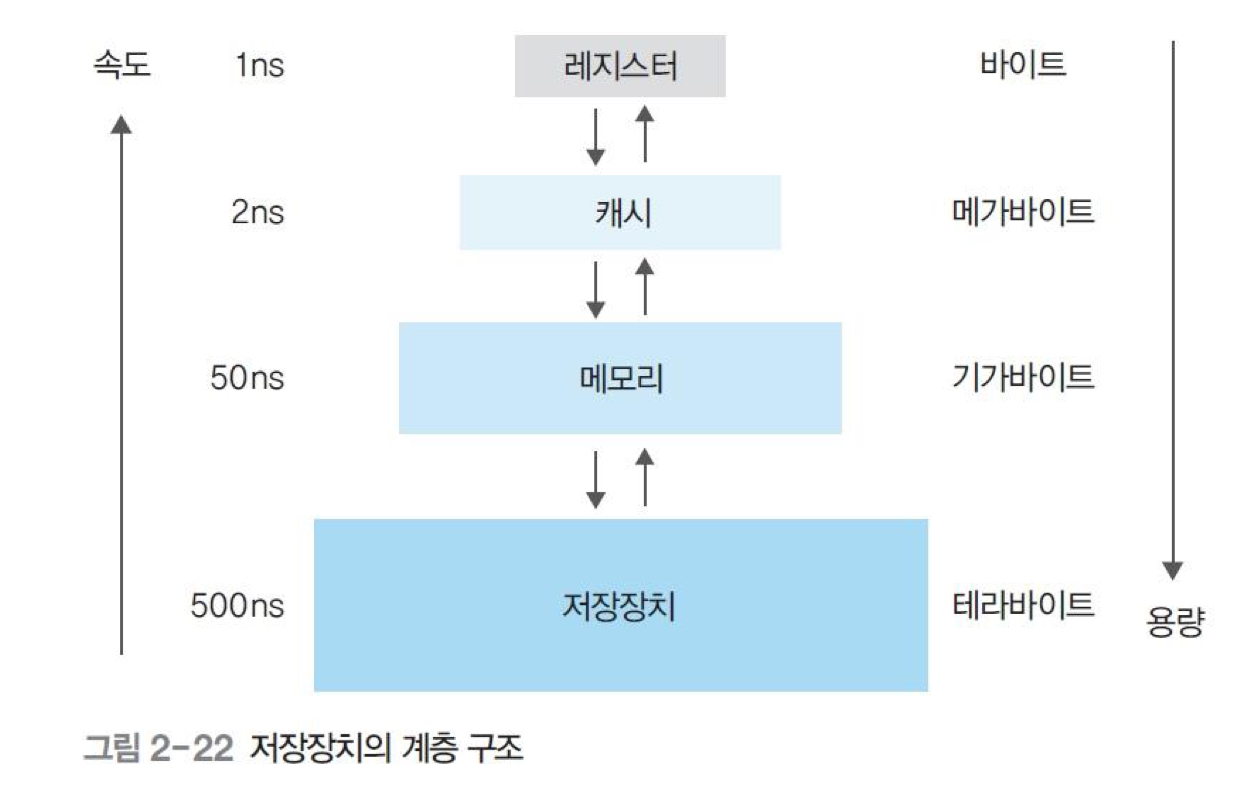
- 컴퓨터는 CPU와 메모리의 협업으로 작업하지만 메모리 속도가 CPU보다 느림
- 저장장치의 계층 구조에서는 CPU와 가까운 쪽에 레지스터나 캐시를 배치하여 CPU가 작업을 빨리 진행할 수 있게 함
- 메모리에서 작업한 내용을 하드디스크와 같은 저렴하고 용량이 큰 저장장치에 저장할 수 있게 함
→ 저장장치의 계층 구조는 사용자가 저렴한 가격으로 용량은 하드디스크처럼 사용하고 작업 속도는 레지스터처럼 빠르게 만들어 줌
- 저장장치의 계층 구조의 문제점 - 중복되는 데이터의 일관성을 유지하는 것
- CPU가 캐시에 저장된 데이터를 변경하면 메모리의 해당 주소에 있는 데이터도 갱신되어야 하는데 변경된 내용을 즉시 반영하지 않고 일정 기간 모았다가 한꺼번에 메모리에 반영하는 지연 쓰기의 경우에는 문제가 됨
- 협업 중인 다른 작업에서 해당 데이터를 읽으려 한다면 일관성이 깨질 수 있음
- 전원이 꺼지면 데이터를 잃을 수 있음
- 버퍼를 사용하는 하드디스크 같은 저장장치에서도 데이터의 일관성이 깨질 수 있음
- 버퍼를 비우지 않았는데 하드웨어를 제거하면 일관성이 무너짐
- 데이터의 일관성 문제는 분산된 데이터베이스에 같은 데이터가 저장된 경우, CPU를 여러 개 사용하는 병렬 컴퓨터의 분산된 메모리 등에서도 발생함
- CPU가 캐시에 저장된 데이터를 변경하면 메모리의 해당 주소에 있는 데이터도 갱신되어야 하는데 변경된 내용을 즉시 반영하지 않고 일정 기간 모았다가 한꺼번에 메모리에 반영하는 지연 쓰기의 경우에는 문제가 됨
인터럽트
개념
- 초기의 컴퓨터 시스템은 주변장치가 많지 않음 → CPU가 직접 입출력장치에서 데이터를 가져오거나 내보냄(폴링(polling) 방식)
- 요리사 모형에 비유 시 요리사가 요리를 하다가 재료가 필요하면 보관 창고에서 직접 가져오는 것
- 폴링 방식에서는 CPU가 입출력장치의 상태를 주기적으로 검사하여 일정한 조건을 만족할 때 데이터를 처리
- CPU가 명령어 해석과 실행이라는 본래 역할 외에 모든 입출력까지 관여해야 함 → 작업 효율 떨어짐
- 인터럽트(interrupt) 방식
- CPU의 작업과 저장장치의 데이터 이동을 독립적으로 운영함으로써 시스템의 효율을 높임
- 데이터의 입출력이 이뤄지는 동안 CPU가 다른 작업을 할 수 있음
- 요리사 모형에 비유하면 요리사 옆에 주방 보조를 두는 것과 같음
- 요리사는 주방 보조에게 필요한 재료를 가져오도록 지시하고 자신은 계속 요리를 함
- 지시를 받은 주방 보조는 재료를 가져다 도마에 올려놓고 재료가 준비되었다는 것을 요리사에게 알려줌
인터럽트 방식의 동작 과정
- CPU가 입출력 관리자에게 입출력 명령을 보냄
- 입출력 관리자는 명령받은 데이터를 메모리에 가져다 놓거나 메모리에 있는 데이터를 저장장치로 옮김
- 데이터 전송이 완료되면 입출력 관리자는 CPU에 완료 신호를 보냄
인터럽트라는 이름이 붙은 이유
입출력 관리자가 CPU에 보내는 완료 신호를 인터럽트라고 한다.
CPU는 입출력 관리자에게 작업 지시를 내리고 다른 일을 하다가 완료 신호를 받으면 하던 일을 중단하고 옮겨진 데이터를 처리한다. 이처럼 하던 작업을 중단하고 처리해야 하는 신호라는 의미에서 인터럽트라는 이름이 붙었다.
- 인터럽트 번호(interrupt number)
- 인터럽트 방식에서는 많은 주변장치 중 어떤 장치의 작업이 끝났는지를 CPU에 알려주기 위해 인터럽트 번호를 사용
- 완료 신호를 보낼 때 장치의 이름 대신 사용하는 고유 번호로 운영체제마다 다름
- 윈도우 운영체제: IRQ(Interrupt ReQuest) - 키보드의 IRQ는 1번, 마우스의 IRQ는 12번, 첫번째 하드디스크의 IRQ는 14번
- 인터럽트 벡터(interrupt vector)
- CPU는 입출력 관리자에게 여러 개의 입출력 작업을 동시에 시킬 수 있음
- 여러 작업이 동시에 완료되고 그때마다 인터럽트를 여러 번 사용해야 함 → 비효율적
- 여러 개의 인터럽트를 하나의 배열로 만든 인터럽트 벡터 사용
인터럽트 처리 과정

- 그림에서 인터럽트 0번과 3번의 작업이 완료되어 인터럽트 0번과 3번이 동시에 발생했다는 것을 알 수 있음
- CPU가 인터럽트 벡터를 받으면 인터럽트 0번과 3번의 작업을 동시에 처리함
- 다양한 종류의 인터럽트
- 사용자가 컴퓨터의 전원 버튼을 눌러 강제로 종료하면 인터럽트 발생
→ CPU는 하던 일을 모두 멈추고 처리 중인 데이터를 안전하게 보관한 뒤 시스템 종료 - 메모리에서 실행 중인 어떤 작업이 자신에게 주어진 메모리 영역을 넘어서 작업하거나 0으로 숫자를 나눌 때도 인터럽트 발생
- 사용자가 컴퓨터의 전원 버튼을 눌러 강제로 종료하면 인터럽트 발생
직접 메모리 접근(DMA; Direct Memory Access)
- 과거의 운영체제: 폴링 방식 → CPU가 메모리나 주변장치에 대한 모든 권한 가짐
- 그러나 효율성을 높이기 위해 인터럽트 방식을 사용 → 입출력 관리자가 데이터 입출력을 맡게 됨
그림 2-25를 참고하자.
- 입출력이 필요할 때 CPU는 입출력 관리자에게 입출력 요청을 보내고 하던 일을 계속함
- 명령을 받은 입출력 관리자는 CPU가 요청한 데이터를 메모리에 가져다 놓아야 함
- 문제는 메모리는 CPU만 접근 권한을 가진 작업 공간이라 입출력 관리자는 접근 불가
- 입출력 관리자에게는 CPU의 허락 없이 메모리에 접근할 수 있는 권한이 필요함
- 이것을 직접 메모리 접근이라 함
데이터 전송을 지시받은 입출력 관리자는 직접 메모리 접근 권한이 있어야 CPU의 관여 없이 작업 완료 가능

메모리 맵 입출력(MMO; Memory Mapped I/O)
- 직접 메모리 접근은 인터럽트 방식의 시스템을 구성하는 필수 요소이나 직접 메모리 접근을 사용하면 메모리가 복잡해짐
- 메모리에는 CPU가 사용하는 데이터와 입출력장치가 사용하는 데이터가 섞여 있음
- 직접 메모리 접근을 통해 들어온 데이터를 메모리에 아무렇게 둔다면 CPU가 사용하는 데이터와 섞여서 관리하기 어려울 것이므로 이를 막기 위해 메모리를 나누어 사용하는 방법이 도입되었음
- 메모리 맵 입출력
- 메모리의 일정 공간을 입출력에 할당하는 기법
- CPU가 사용하는 메모리 공간과 직접 메모리 접근을 통해 들어오고 나가는 데이터를 위한 공간을 분리하는 것

사이클 훔치기(cycle stealing)
CPU와 직접 메모리 접근이 동시에 메모리에 접근하려 한다면 어떤 일이 발생할까?
- 이 경우에 누군가는 양보해야 하는데 보통은 CPU가 메모리 사용 권한을 양보한다.
- CPU의 작업 속도보다 입출력장치의 속도가 느리기 때문
- CPU 입장에서는 직접 메모리 접근이 사이클(순서)을 훔쳐 간 것이 되기 때문에 이러한 상황을 사이클 훔치기라고 함
멀티 프로세싱
멀티코어 시스템
- 단일 프로세서 시스템(single processor system)
- 과거에 사용된 컴퓨터 한 대에 프로세서(CPU)가 하나 달린 시스템
- 프로세서 하나가 한 번에 하나의 작업을 처리할 수 있음
- 성능 향상 방법
- CPU 클록을 높이기 → 발열 문제 발생 → 5GHz가 넘는 CPU 개발 어려움
- 캐시의 크기 늘리기 → 비용 문제
- 멀티 프로세서 시스템(multi processor system)
- 컴퓨터의 성능을 높이기 위해 프로세서를 여러 개 설치하여 사용하는 시스템
- CPU 성능을 향상하기 위해 CPU의 핵심 기능을 가진 코어를 여러 개 만들거나 동시에 실행 가능한 명령의 개수를 늘리는 방법
- 프로세서마다 레지스터와 캐시를 가짐
- 모든 프로세서가 시스템 버스를 통하여 메인메모리를 공유
- 장점: 많은 작업을 동시에 실행시킬 수 있음
- 멀티코어(multi-core) 시스템
- 단일 프로세서 시스템을 멀티 프로세서 시스템으로 바꾸려면 보드의 설계 변경을 비롯한 많은 변화 필요
- 기존의 시스템을 유지한 채 멀티 프로세싱을 할 수 있게 하는 시스템을 멀티코어 시스템이라 함
- 하나의 칩에 CPU의 핵심이 되는 코어를 여러 개 만들어 여러 작업을 동시에 처리할 수 있음
- 예시) CPU의 사양에 듀얼코어(코어 2개), 쿼드코어(코어 4개)
CPU 멀티스레드
하나의 코어에서 2개 이상의 명령어를 처리하는 방법이다. 레스토랑에 요리사가 2명 있는 경우, 두 가지 요리를 동시에 진행할 수 있다. 이렇게 하나의 코어에서 여러 개의 명령어를 동시에 처리하는 것을 명령어 병렬 처리(instruction parallel processing)이다.

- 기존 방식으로 볶음밥 3개를 만들려면 120분이 걸리지만 이런 방식으로 진행하면 60분 만에 볶음밥 3개를 만들 수 있음
- 한 주방에서 여러 개의 볶음밥을 동시에 조리하는 것 = CPU 사양으로 가져오면 하나의 코어에 여러 개의 스레드를 이용하는 방식
- 여러 개 스레드를 동시에 처리하는 방법을 CPU 멀티스레드라고 한다.
- 인텔의 하이퍼 스레드
- 명령어 병렬 처리로 코어는 하나이지만 2개의 명령어가 거의 동시에 처리되기 때문에 마치 코어가 2개 있는 것처럼 보이는 병렬 처리 방식
- 하나의 코어에서 2개의 명령어를 거의 동시에 실행함
현대의 CPU는 하나의 칩에 멀티코어와 명령어 병렬 처리 기능을 한꺼번에 구현함
- [예시] 인텔의 i7-3770 CPU
- 4코어와 하이퍼 스레드 지원
- 코어 4개에 명령어 병렬 처리(하이퍼 스레드)가 코어 2개씩 작동하기 때문에 논리 프로세서의 개수는 8개가 되어 CPU가 8개 달린 컴퓨터처럼 보인다.
CPU 관련 통용 법칙
1. 무어의 법칙(Moore's law)
인텔의 공동 창업자인 고든 무어는 CPU 속도가 24개월마다 2배 빨라진다는 무어의 법칙을 주장했다. CPU는 자체 발열 문제로 속도를 5GHz 이상 높이기 어렵기 때문에 요즘에는 처리 속도를 올리는 대신 멀티코어를 장착하는 방향으로 나아가고 있다. 멀티코어는 CPU의 핵심 부품인 코어를 여러 개로 구성한 것으로 CPU를 여러 개 사용하는 것과 같은 효과를 낸다. 듀얼코어를 장착하면 CPU 2개를 동시에 사용하는 효과를 얻을 수 있다. 멀티코어와 함께 멀티스레드도 많이 사용된다. 멀티스레드는 하나의 코어에서 여러 개의 명령어를 동시에 실행하는 기술이다. PC용 CPU는 하나의 코어에 2개의 스레드를 사용하는 4코어 8스레드 제품이 판매되고 있다.
2. 암달의 법칙(Amdahl's law)
진 암달은 컴퓨터 시스템의 일부를 개선할 때 전체 시스템에 미치는 영향과의 관계를 수식으로 나타낸 암달의 법칙을 만들었다. 이 법칙에 따르면 주변장치의 향상 없이 CPU 속도를 2GHz에서 4GHz로 늘리더라도 컴퓨터 성능이 2배 빨라지지는 않는다. CPU 속도를 올려도 메모리를 비롯한 주변장치가 CPU의 발전 속도를 따라가지 못해 컴퓨터의 전반적인 성능은 저하된다. 암달의 법칙은 멀티코어에도 적용되는데, 코어가 하나인 싱글코어 대신 듀얼코어를 사용하더라도 CPU 내 다른 부품의 병목 현상으로 CPU 성능이 2배가 되지 않는다.
'OS > 쉽게 배우는 운영체제' 카테고리의 다른 글
| [쉽게 배우는 운영체제] 5. 프로세스 동기화 (0) | 2024.03.20 |
|---|---|
| [쉽게 배우는 운영체제] 4. CPU 스케줄링 (6) | 2024.03.11 |
| [쉽게 배우는 운영체제] 3. 프로세스와 스레드 (0) | 2024.02.19 |
| [쉽게 배우는 운영체제] 2. 컴퓨터 구조와 성능 향상(연습문제) (0) | 2024.02.13 |
| [쉽게 배우는 운영체제] 1. 운영체제의 개요 (1) | 2024.02.06 |
