
익명 클래스로 다양한 동작을 구현할 수 있지만 코드가 깔끔하지 않다. 깔끔하지 않은 코드는 이전 내용에서 배운 동적 파라미터를 실전에 적용하는 것을 막는 요소다. 이때 더 깔끔한 코드로 동작을 구현하고 전달하는 람다 표현식을 사용해보자.
람다란 무엇인가?
람다 표현식은 메서드로 전달할 수 있는 익명 함수를 단순화한 것이라고 할 수 있다. 람다 표현식에는 이름은 없지만, 파라미터 리스트, 바디, 반환 형식, 발생할 수 있는 예외 리스트는 가질 수 있다.
람다의 특징
익명
• 보통의 메서드와 달리 이름이 없으므로 익명이라 표현한다.
• 구현해야 할 코드에 대한 걱정거리가 줄어든다.
함수
• 람다는 메서드처럼 특정 클래스에 종속되지 않으므로 함수라고 부른다.
• 하지만 메서드처럼 파라미터 리스트. 바디, 반환 형식, 가능한 예외 리스트를 포함한다.
전달
• 람다 표현식을 메서드 인수로 전달하거나 변수로 저장할 수 있다.
간결성
• 익명 클래스처럼 많은 자질구레한 코드를 구현할 필요 없다.
람다라는 용어는 미적분학 학계에서 개발한 시스템에서 유래했다. 람다가 중요한 이유는 람다를 이용해서 간결한 방식으로 코드를 전달할 수 있기 때문이다. 예시로 커스텀 Comparator 객체를 기존보다 간단하게 구현할 수 있다.
- 기존의 코드
Comparator<Apple> byWeight = new Comparator<Apple>() {
public int compare(Apple a1, Apple a2) {
return a1.getWeight().compareTo(a2.getWeight());
}
};- 람다를 이용한 코드
Comparator<Apple> weight =
(Apple a1, Apple a2) -> a1.getWeight().compareTo(a2.getWeight());훨씬 간결하게 표현할 수 있다.
람다 표현식은 파라미터, 화살표, 바디로 이루어진다.

- 파라미터 리스트 - Comparator의 compare 메서드 파라미터(사과 두 개)
- 화살표 - 화살표(->)는 람다의 파라미터 리스트와 바디를 구분한다.
- 람다 바디 - 두 사과의 무게를 비교한다. 람다의 반환값에 해당하는 표현식이다.
아래는 자바 8의 유효한 람다 표현식이다.
(String s) -> s.length()
(Apple a) -> a.getWeight() > 150
//람다 표현식에는 return이 함축되어 있으므로 명시적으로 사용하지 않아도 된다.
(int x, int y) -> { //int 형식의 파라미터 두 개를 가지며 리턴 값이 없다(void).
System.out.println("Result:");
System.out.println(x + y); //람다 표현식은 여러 행의 문장을 포함할 수 있다.
}
() -> 42 // 파라미터가 없으며 int 42를 반환한다.
(Apple a1, Apple a2) -> a1.getWeight().compareTo(a2.getWeight())
//Apple 형식의 파라미터 두 개를 가지며 int(두 사과의 무게 비교 결과)를 반환한다.어디에, 어떻게 람다를 사용할까?
동적 파라미터화에서 구현했던 필터 메서드에도 람다를 활용할 수 있다.
List<Apple> greenApples =
filter(inventory, (Apple a) -> GREEN.equals(a.getColor()));
그래서 정확히 어디에서 람다를 사용할 수 있을까? 함수형 인터페이스라는 문맥에서 람다 표현식을 사용할 수 있다. 위 예제에서는 함수형 인터페이스 Predicate<T>를 기대하는 filter 메서드의 두 번째 인수로 람다 표현식을 전달했다. 이제 함수형 인터페이스가 무엇인지 살펴보자.
함수형 인터페이스
함수형 인터페이스란 정확히 하나의 추상 메서드를 지정하는 인터페이스이다.
public interface Comparator<T> {
boolean test(T t);
}
public interface Runnable {
void run();
}
public interface ActionListener extends EventListener {
void actionPerformed(ActionEvent e);
}
public interface Callable<V> {
V call() throws Exception;
}
public interface PrivilegeAction<T> {
T run();
}인터페이스는 디폴트 메서드(인터페이스의 메서드를 구현하지 않은 클래스를 고려해서 기본 구현을 제공하는 바디를 포함하는 메서드)를 포함할 수 있다. 많은 디폴트 메서드가 있더라도 추상 메서드가 오직 하나면 함수형 인터페이스다.
함수형 인터페이스로 무엇을 할 수 있을까?
람다 표현식으로 함수형 인터페이스의 추상 메서드 구현을 직접 전달할 수 있으므로 전체 표현식을 함수형 인터페이스의 인스턴스로 취급(기술적으로 따지면 함수형 인터페이스를 구현한 클래스의 인스턴스)할 수 있다. 또한 익명 내부 클래스 같은 기능을 구현할 수 있다. 다음 예시로 Runnable이 오직 하나의 추상 메서드 run을 정의하는 함수형 인터페이스임을 보여준다.
Runnable r1 = () -> System.out.println("run 1"); //람다 사용
Runnable r2 = new Runnable() { //익명 클래스 사용
public void run() {
System.out.println("run 2");
}
};
public static void process(Runnable r) {
r.run();
}
process(r1);
process(r2);
process(() -> System.out.println("run 3")); //직접 전달된 람다 표현식함수 디스크립터
함수형 인터페이스의 추상 메서드 시그니처는 람다 표현식의 시그니처를 가리킨다. 람다 표현식의 시그니처를 서술하는 메서드를 함수 디스크립터라고 부른다. 예를 들어 Runnable 인터페이스의 유일한 추상 메서드 run은 인수와 반환값이 없으므로(void) Runnable 인터페이스는 인수와 반환값이 없는 시그니처로 생각할 수 있다.
람다와 함수형 인터페이스를 가리키는 특별한 표기법은 다음과 같다.
`() -> void` : 파라미터에 리스트가 없으며 void를 반환하는 함수(앞의 Runnable)
`(Apple, Apple) -> int` : 두 개의 Apple을 인수로 받아 int를 반환하는 함수
자바 언어 명세에 따라 한 개의 void 메서드 호출은 중괄호로 감쌀 필요가 없다.
ex) process(() -> System.out.println("This is awsome"));
'왜 함수형 인터페이스를 인수로 받는 메서드에만 람다 표현식을 사용할 수 있을까?'라는 의문이 생길 수 있다. 대부분의 자바 프로그래머가 하나의 추상 메서드를 갖는 인터페이스(예를 들면 이벤트 처리 인터페이스)에 이미 익숙하고, 언어를 더 복잡하지 않게 하고자 했기 때문이다.
람다 활용 : 실행 어라운드 패턴
자원처리(예를 들면 데이터베이스의 파일 처리)에 사용하는 순환 패턴은 자원을 열고 처리 후 자원을 닫는 순서로 이뤄진다. 설정과 정리 과정은 대부분 비슷하다. 즉, 실제 자원을 처리하는 코드를 설정과 정리 두 과정이 둘러싸는 형태를 갖는다. 아래 그림과 같은 형식의 코드를 실행 어라운드 패턴이라고 부른다.

public String processFile() throws IOException {
try (BufferedReader br =
new BufferedReader(new FileReader("data.txt"))) {
return br.readLine(); //실제 필요한 작업을 하는 행
}
}예제에서 try-with-resources 구문을 사용하여 자원을 명시적으로 닫을 필요가 없으므로 간결한 코드를 구현하는 데 도움을 준다.
1단계 : 동작 파라미터화를 기억하라
현재 코드는 파일에서 한 번에 한 줄만 읽을 수 있다. 한 번에 두 줄을 읽거나 가장 자주 사용되는 단어를 반환하려면 어떻게 해야 할까? 기존의 정리 설정, 정리 과정은 재사용하고 processFile 메서드만 다른 동작을 수행하도록 명령할 수 있다면 좋을 것이다. 그렇다. processFile의 동작을 파라미터화하는 것이다. processFile 메서드가 BufferedReader를 이용해서 다른 동작을 수행할 수 있도록 processFile 메서드로 동작을 전달해야 한다.
람다를 이용해서 processFile 메서드가 한 번에 두행을 읽게 하려면 다음과 같이 코드를 수정할 수 있다.
String result = processFile((BufferedReader br) ->
br.readLine() + br.readLine());2단계 : 함수형 인터페이스를 이용해서 동작 전달
함수형 인터페이스 자리에 람다를 사용할 수 있다. BufferedReader -> String과 IOException을 던질 수 있는 시그니처와 일치하는 함수형 인터페이스를 BufferedReaderProcessor라고 정의하자.
@FunctionalInterface
public interface BufferedReaderProcessor {
String process(BufferedReader b) throws IOException;
}정의한 인터페이스를 processFile 메서드의 인수로 전달할 수 있다.
public String processFile(BufferedReaderProcessor p) throws IOException {
...
}3단계 : 동작 실행
이제 BufferedReaderProcessor에 정의된 process 메서드의 시그니처(BufferedReader -> String)와 일치하는 람다를 전달할 수 있다. 람다 표현식으로 함수형 인터페이스의 추상 메서드 구현을 직접 전달할 수 있으며 전달된 코드는 함수형 인터페이스의 인스턴스로 전달된 코드와 같은 방식으로 처리한다. 따라서 processFile 바디 내에서 BufferedReaderProcessor 객체의 prcoess를 호출할 수 있다.
public String processFile(BufferedReaderProcessor p) throws IOException {
try (BufferedReader br =
new BufferedReader(new FileReader("data.txt"))) {
return p.process(br); //BufferedReader 객체 처리
}
}4단계 : 람다 전달
람다를 이용해서 다양한 동작을 processFile 메서드로 전달할 수 있다.
- 한 행을 처리하는 코드
String oneLine = processFile((BufferedReader br) -> br.readLine());- 두 행을 처리하는 코드
String twoLines = processFile((BufferedReader br) -> br.readLine() + br.readLine());
함수형 인터페이스 사용
함수형 인터페이스는 오직 하나의 추상 메서드를 지정하고 추상 메서드는 람다 표현식의 시그니처를 묘사한다. 함수형 인터페이스의 추상 메서드 시그니처를 함수 디스크립터라고 한다. 다양한 람다 표현식을 사용하려면 공통의 함수 디스크립터를 기술하는 함수형 인터페이스 집합이 필요하다.
Predicate
java.util.function.Predicate<T> 인터페이스는 test라는 추상 메서드를 정의하며 test는 제네릭 형식 T의 객체를 인수로 받아 불리언을 반환한다. 따로 정의할 필요 없이 바로 사용할 수 있다. T 형식의 객체를 사용하는 불리언 표현식이 필요한 상황에서 Predicate 인터페이스를 사용할 수 있다.
@FunctionalInterface
public interface Predicate<T> {
boolean test(T t);
}
public <T> List<T> filter(List<T> list, Predicate<T> p) {
List<T> results = new ArrayList<>();
for(T t : list) {
if(p.test(t)) {
results.add(t);
}
}
return results;
}
Predicate<String> nonEmptyStringPredicate = (String s) -> !s.isEmpty();
List<String> nonEmpty = filter(listOfStrings, nonEmptyStringPredicate);Predicate 인터페이스의 자바독 명세를 보면 and나 or같은 메서드도 있다.
Consumer
java.util.function.Consumer<T> 인터페이스는 제네릭 형식 T 객체를 받아서 void를 반환하는 accept라는 추상 메서드를 정의한다. T 형식의 객체를 인수로 받아서 어떤 동작을 수행하고 싶을 때 Consumer 인터페이스를 사용할 수 있다. 예를 들어 Integer 리스트를 인수로 받아서 각 항목에 어떤 동작을 수행하는 forEach 메서드를 정의할 때 Consumer를 활용할 수 있다.
@FunctionalInterface
public interface Consumer<T> {
void accept(T t);
}
public <T> void forEach(List<T> list, Consumer<T> c) {
for(T t : list) {
c.accept(t);
}
}
forEach(
Arrays.asList(1,2,3,4,5),
(Integer i) -> System.out.println(i)
); //Consumer의 accept 메서드를 구현하는 람다Function
java.util.function.Function<T, R> 인터페이스는 제네릭 형식 T를 인수로 받아서 제네릭 형식 R 객체를 반환하는 추상 메서드 apply를 정의한다. 입력을 출력으로 매핑하는 람다를 정의할 때 Function 인터페이스를 활용할 수 있다. 예를 들면 사과의 무게 정보를 추출하거나 문자열을 길이와 매핑하는 경우, 또는 아래 예시처럼 String 리스트를 인수로 받아 각 String의 길이를 포함하는 Integer 리스트로 변환하는 map 메서드와 같은 경우가 있다.
@FunctionalInterface
public interface Function<T, R> {
R apply(T t);
}
public <T, R> List<R> map(List<T> list, Function<T, R> f) {
List<R> result = new ArrayList<>();
for(T t : list) {
result.add(f.apply(t));
}
return result;
}
//[7, 2, 6]
List<Integer> l = map(
Arrays.asList("lambdas", "in", "action"),
(String s) -> s.length()
); //Function의 apply 메서드를 구현하는 람다
기본형 특화
자바의 모든 형식은 참조형(Integer, Object, List, ...) 아니면 기본형(int, double, byte, ...)에 해당한다. 하지만 제네릭 파라미터(Consumer<T>의 T)에는 참조형만 사용할 수 있다. 제네릭의 내부 구현 때문에 어쩔 수 없는 일이다. 자바에서는 기본형을 참조형으로 변환하는 기능을 제공한다. 이 기능을 박싱이라고 한다. 참조형을 기본형으로 변환하는 반대 동작을 언박싱이라고 한다. 또한 프로그래머가 편리하게 코드를 구현할 수 있도록 박싱과 언박싱이 자동으로 이루어지는 오토박싱이라는 기능도 제공한다.
- int가 Integer로 박싱되는 코드
List<Integer> list = new ArrayList<>();
for (int i = 300; i < 400; i++) {
list.add(i);
}하지만 이런 변환 과정은 비용이 소모된다. 박싱한 값은 기본형을 감싸는 래퍼며 힙에 저장된다. 따라서 박싱한 값은 메모리를 더 소비하며 기본형을 가져올 때도 메모리를 탐색하는 과정이 필요하다.
자바 8에서는 기본형을 입출력으로 사용하는 상황에서 오토박싱 동작을 피할 수 있도록 특별한 버전의 함수형 인터페이스를 제공한다. 예를 들어 아래 예제에서 IntPredicate는 1000이라는 값을 박싱하지 않지만, Predicate<Integer>는 1000이라는 값을 Integer 객체로 박싱한다.
public interface IntPredicate {
boolean test(int t);
}
IntPredicate evenNumbers = (int i) -> i % 2 == 0;
evenNumbers.test(1000); //참(박싱 없음)
Predicate<Integer> oddNumbers = (Integer i) -> i % 2 != 0;
oddNumbers.test(1000); //거짓(박싱)일반적으로 특정 형식을 입력으로 받는 함수형 인터페이스의 이름 앞에는 DoublePredicate, IntConsumer, LongBinaryOperator, IntFunction처럼 형식명이 붙는다. Function 인터페이스는 ToIntFunction<T>, IntToDoubleFunction 등 다양한 출력 형식 파라미터를 제공한다.

- 람다와 함수형 인터페이스의 예시
| 사용 사례 | 람다 예제 | 대응하는 함수형 인터페이스 |
| 불리언 표현 | (List<String> list) -> list.isEmpty() |
Predicate<List<String>> |
| 객체 생성 | () -> new Apple(10) | Supplier<Apple> |
| 객체에서 소비 | (Apple a) -> System.out.println(a.getWeight()) |
Consumer<Apple> |
| 객체에서 선택/추출 | (String s) -> s.length() | Function<String, Integer> ToIntFunction<String> |
| 두 값 조합 | (int a, int b) -> a * b | IntBinaryOperator |
| 두 객체 비교 | (Apple a1, Apple a2) -> a1.getWeight() .compareTo(a2.getWeight()) |
Comparator<Apple> BiFunction<Apple, Apple, Integer> ToIntBiFunction<Apple, Apple> |
예외, 람다, 함수형 인터페이스의 관계
함수형 인터페이스는 확인된 예외를 던지는 동작을 허용하지 않는다. 즉, 예외를 던지는 람다 표현식을 만들려면 확인된 예외를 선언하는 함수형 인터페이스를 직접 정의하거나 람다를 try/catch 블록으로 감싸야 한다.
- 예시 - IOException을 명시적으로 선언하는 함수형 인터페이스 BufferedReaderProcessor
@FunctionalInterface
public interface BufferedReaderProcessor {
String process(BufferedReader b) throws IOException;
}
BufferedReaderProcessor p = (BufferedReader br) -> br.readLine();우리는 Function<T, R> 형식의 함수형 인터페이스를 기대하는 API를 사용하고 있으며 직접 함수형 인터페이스를 만들기 어려운 상황이다. 이런 상황에서는 다음 예제처럼 명시적으로 확인된 예외를 잡을 수 있다.
Function<BufferedReader, String> f = (BufferedReader b) -> {
try {
return b.readLine();
}
catch(IOException e) {
throw new RuntimeException(e);
}
};형식 검사, 형식 추론, 제약
람다로 함수형 인터페이스의 인스턴스를 만들 수 있다. 람다 표현식 자체에는 람다가 어떤 함수형 인터페이스를 구현하는지의 정보가 포함되어 있지 않다. 따라서 람다 표현식을 더 제대로 이해하려면 람다의 실제 형식을 파악해야 한다.
형식 검사
람다가 사용하는 콘텍스트를 이용해서 람다의 형식을 추론할 수 있다. 어떤 콘텍스트(람다가 전달될 메서드 파라미터나 람다가 할당되는 변수 등)에서 기대되는 람다 표현식의 형식을 대상 형식이라고 부른다.
List<Apple> heavierThan150g =
filter(inventory, (Apple apple) -> apple.getWeight() > 150);위 코드의 형식 확인 과정은 다음과 같은 순서로 진행된다.
- filter 메서드의 선언을 확인한다.
- filter 메서드는 두 번째 파라미터로 Predicate<Apple> 형식(대상 형식)을 기대한다.
- Predicate<Apple>은 test라는 한 개의 추상 메서드를 정의하는 함수형 인터페이스다.
- test 메서드는 Apple을 받아 boolean을 반환하는 함수 디스크립터를 묘사한다.
- filter 메서드로 전달된 인수는 이와 같은 요구사항을 만족해야 한다.
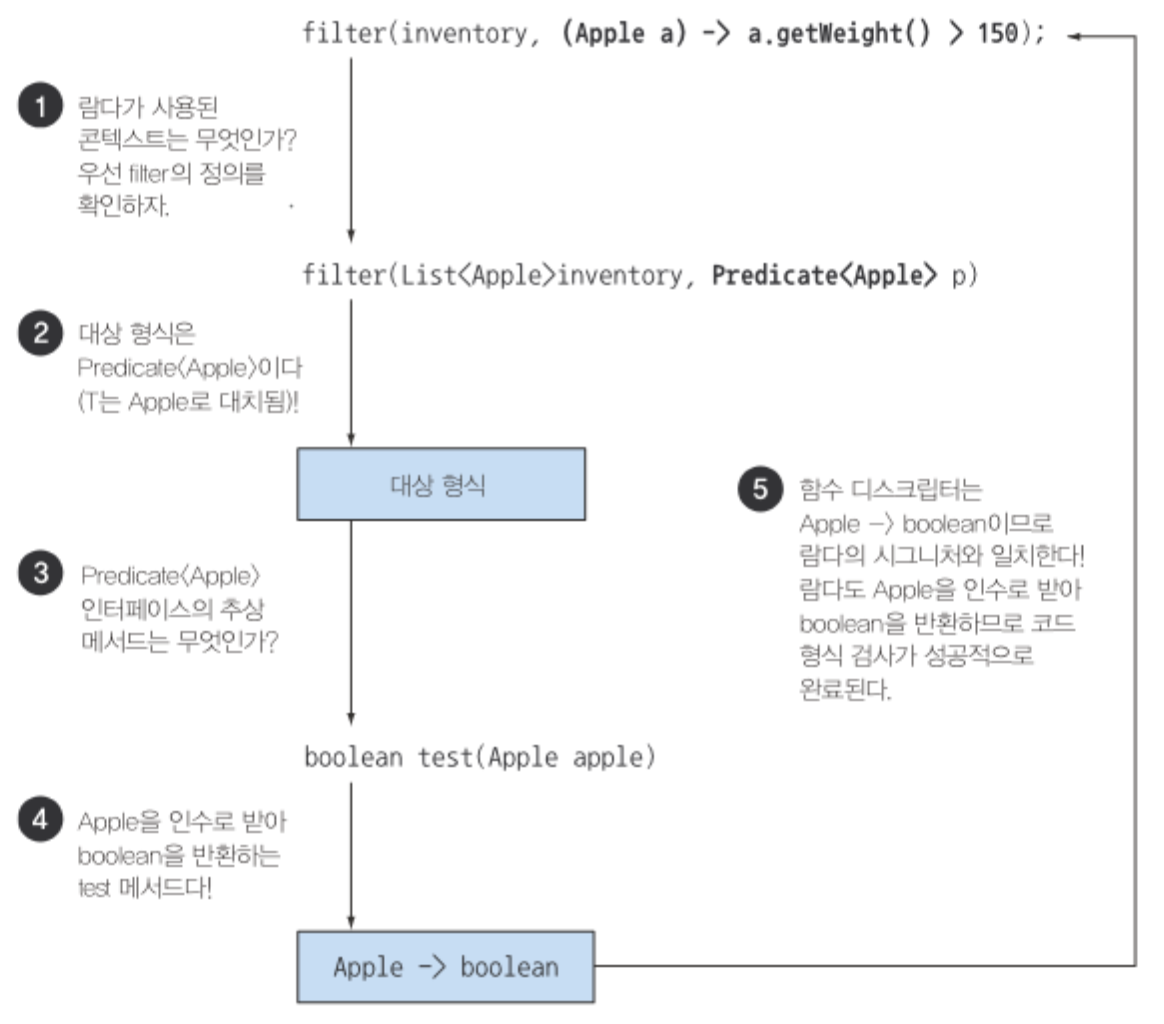
위 예제에서 람다 표현식은 Apple을 인수로 받아 boolean을 반환하므로 유효한 코드다. 람다 표현식이 예외를 던질 수 있다면 추상 메서드도 같은 예외를 던질 수 있도록 throws로 선언해야 한다.
같은 람다, 다른 함수형 인터페이스
대상 형식이라는 특징 때문에 같은 람다 표현식이더라도 호환되는 추상 메서드를 가진 다른 함수형 인터페이스로 사용될 수 있다.
예를 들어 Callable과 PrivilegedAction 인터페이스는 인수를 받지 않고 제네릭 형식 T를 반환하는 함수를 정의한다. 따라서 다음 두 할당문은 모두 유효한 코드다.
Callable<Integer> c = () -> 42;
PrivilegedAction<Integer> p = () -> 42;위와 비슷하게 하나의 람다 표현식을 다양한 함수형 인터페이스에 사용할 수 있다.
Comparator<Apple> c1 =
(Apple a1, Apple a2) -> a11.getWeight().compareTo(a2.getWeight());
ToIntBiFunction<Apple, Apple> c2 =
(Apple a1, Apple a2) -> a1.getWeight().compareTo(a2.getWeight());
BiFunction<Apple, Apple, Integer> c3 =
(Apple a1, Apple a2) -> a1.getWeight().compareTo(a2.getWeight());
람다의 바디에 일반 표현식이 있으면 void를 반환하는 함수 디스크립터와 호환된다(물론 파라미터 리스트도 호환되어야 함).
예를 들어 다음 두 행의 예제에서 List의 add 메서드는 Consumer 콘텍스트(T -> void)가 기대하는 void 대신 boolean을 반환하지만 유효한 코드다.
//Predicate는 불리언 반환값을 갖는다.
Predicate<String> p = s -> list.add(s);
//Consumer는 void 반환값을 갖는다.
Consumer<String> b = s -> list.add(s):
같은 함수형 디스크립터를 가진 두 함수형 인터페이스를 갖는 메서드를 오버로딩할 때 어떤 메서드의 시그니처가 사용되어야 하는지 명시적으로 구분하도록 람다를 캐스트할 수 있다.
예를 들어 execute(() -> {})라는 람다 표현식이 있다면 Runnable과 Action의 함수 디스크립터가 같으므로 누구를 가리키는지가 명확하지 않다.
public void execute(Runnable runnable) {
runnable.run();
}
public void execute(Action<T> action) {
action.act();
}
@FunctionalInterface
interface Action {
void act();
}하지만 다음과 같이 캐스트하면 누구를 호출할 것인지가 명확해진다.
execute((Action) () -> {});형식 추론
코드를 좀 더 단순화할 수 있는 방법이 있다. 자바 컴파일러는 람다 표현식이 사용된 콘텍스트(대상 형식)를 이용해서 람다 표현식과 관련된 함수형 인터페이스를 추론한다. 즉, 대상 형식을 이용해서 함수 디스크립터를 알 수 있으므로 컴파일러는 람다의 시그니처도 추론할 수 있다. 결과적으로 컴파일러는 람다 표현식의 파라미터 형식에 접근할 수 있으므로 람다 문법에서 이를 생략할 수 있다. 즉, 자바 컴파일러는 다음처럼 람다 파라미터 형식을 추론할 수 있다.
List<Apple> greenApples =
filter(inventory, apple -> GREEN.equals(apple.getColor()));여러 파라미터를 포함하는 람다 표현식에서는 코드 가독성 향상이 더 두드러진다. 예를 들어 다음은 Comparator 객체를 만드는 코드다.
Comparator<Apple> c = //형식 추론 x
(Apple a1, Apple a2) -> a1.getWeight().compareTo(a2.getWeight());
Comparator<Apple> c = //형식 추론 o
(a1, a2) -> a1.getWeight().compareTo(a2.getWeight());상황에 따라 명시적으로 형식을 포함하는 것이 좋을 때도 있고 형식을 배제하는 것이 가독성을 향상 시킬 때도 있으므로 스스로 어떤 코드가 가독성을 향상시킬 수 있는지 결정해야 한다.
지역 변수 사용
지금까지 살펴본 모든 람다 표현식은 인수를 자신의 바디 안에서만 사용했다. 하지만 람다 표현식에서는 익명 함수가 하는 것처럼 자유 변수(파라미터로 넘겨진 변수가 아닌 외부에서 정의된 변수)를 활용할 수 있다. 이와 같은 동작을 람다 캡처링이라고 부른다.
다음은 portNumber 변수를 캡처하는 람다 예제이다.
int portNumber = 1337;
Runnable r = () -> System.out.println(portNumber);람다는 인스턴스 변수와 정적 변수를 자유롭게 캡처(자신의 바디에서 참조할 수 있도록)할 수 있다. 하지만 그러려면 지역 변수는 명시적으로 final로 선언되어 있어야 하거나 실질적으로 final로 선언된 변수와 똑같이 사용되어야 한다. 즉, 람다 표현식은 한 번만 할당할 수 있는 지역 변수를 캡처할 수 있다. 예를 들어 다음 예제는 portNumber에 값을 두 번 할당하므로 컴파일할 수 없는 코드다.
int portNumber = 1337;
Runnable r = () -> System.out.println(portNumber);
portNumber = 31337;
지역 변수의 제약
내부적으로 인스턴스 변수와 지역 변수는 태생부터 다르다.
인스턴스 변수는 힙에 저장되는 반면 지역 변수는 스택에 위치한다. 람다에서 지역 변수에 바로 접근할 수 있다는 가정하에 람다가 스레드에서 실행된다면 변수를 할당한 스레드가 사라져서 변수 할당이 해제되었는데도 람다를 실행하는 스레드에서는 해당 변수에 접근하려 할 수 있다. 따라서 자바 구현에서는 원래 변수에 접근을 허용하는 것이 아니라 자유 지역 변수의 복사본을 제공한다. 따라서 복사본의 값이 바뀌지 않아야 하므로 지역 변수에는 한 번만 값을 할당해야 한다는 제약이 생긴 것이다.
또한 지역 변수의 제약 때문에 외부 변수를 변화시키는 일반적인 명령형 프로그래밍 패턴에 제동을 걸 수 있다.
메서드 참조
메서드 참조를 이용하면 기존의 메서드 정의를 재활용해서 람다처럼 전달할 수 있다.
- 기존 코드
inventory.sort((Apple a1, Apple a2) ->
a1.getWeight().compareTo(a2.getWeight()));- 메서드 참조와 java.util.Comparator.comparing을 활용한 코드
inventory.sort(comparing(Apple::getWeight));요약
메서드 참조를 이용하면 기존 메서드 구현으로 람다 표현식을 만들 수 있다. 이때 명시적으로 메서드명을 참조함으로써 가독성을 높일 수 있다. 메서드명 앞에 구분자(::)를 붙이는 방식으로 메서드 참조를 활용할 수 있다.
| 람다 | 메서드 참조 단축 표현 |
| (Apple apple) -> apple.getWeight() | Apple::getWeight |
| () -> Thread.currentThread().dumpStack() | Thread.currentThread()::dumpStack |
| (str, i) -> str.substring(i) | String::substring |
| (String s) -> System.out.println(s) | System.out::println |
| (String s) -> this.isValidName(s) | this::isValidName |
메서드 참조를 만드는 방법
- 정적 메서드 참조
Integer의 parseInt 메서드는 Integer::parseInt로 표현 가능 - 다양한 형식의 인스턴스 메서드 참조
String의 length 메서드는 String::length로 표현 가능 - 기존 객체의 인스턴스 메서드 참조
Transaction 객체를 할당받은 expensiveTransaction 지역 변수가 있고, Transaction 객체에는 getvalue 메서드가 있다면 이를 expensiveTransaction::getValue라고 표현 가능
세 번째 유형의 메서드 참조는 비공개 헬퍼 메서드를 정의한 상황에서 유용하게 활용 가능하다.
private boolean isValidName(String string) {
return Character.isUpperCase(string.charAt(0));
}이제 Predicate<String>를 필요로 하는 적당한 상황에서 메서드 참조를 사용할 수 있다.
filter(words, this::isValidName)
예제를 통해 메서드 참조 활용법을 확인하자. List에 포함된 문자열을 대소문자를 구분하지 않고 정렬하는 프로그램을 구현하려 한다. List의 sort 메서드는 인수로 Comparator를 기대한다. Comparator는 (T, T) -> int라는 함수 디스크립터를 갖는다. String 클래스에 정의되어 있는 compareToIgnoreCase 메서드로 람다 표현식을 정의할 수 있다.
List<String> str = Arrays.asList("a","b","A","B");
str.sort((s1,s2) -> s1.compareToIgnoreCase(s2));
Comparator의 함수 디스크립터와 호환되는 람다 표현식 시그니처도 있다. 위에서 설명한 기법을 이용하면 다음처럼 줄일 수 있다.
List<String> str = Arrays.asList("a","b","A","B");
str.sort(String::compareToIgnoreCase);메서드 참조는 콘텍스트의 형식과 일치해야 한다.
생성자 참조
ClassName::new처럼 클래스명과 new 키워드를 이용해서 기존 생성자의 참조를 만들 수 있다. 이것은 정적 메서드의 참조를 만드는 방법과 비슷하다. 예를 들어 인수가 없는 생성자, 즉 Supplier의 () -> Apple과 같은 시그니처를 갖는 생성자가 있다고 가정하자.
Supplier<Apple> c1 = Apple:new;
Apple a1 = c1.get();
//Supplier의 get 메서드를 호출해서 새로운 Apple 객체를 만들 수 있다.위 예제는 다음 코드와 같다.
Supplier<Apple> c1 = () -> new Apple(); //디폴트 생성자를 가진 Apple 생성
Apple a1 = c1.get(); //get 메서드를 호출해 새로운 Apple 객체 생성
Apple(Integer weight)라는 시그니처를 갖는 생성자는 Function 인터페이스의 시그니처와 같다.
Function<Integer, Apple> c2 = (weight) -> new Apple(weight);
Apple a2 = c2.apply(110);
다음 코드에서 Integer를 포함하는 리스트의 각 요소를 우리가 정의했더 map과 같은 메서드를 이용해서 Apple 생성자로 전달한다. 결과적으로 다양한 무게를 포함하는 사과 리스트가 만들어진다.
List<Integer> weights = Arrays.asList(7,3,4,10);
List<Apple> apples = map(weights, Apple::new);
public List<Apple> map(List<Integer> list, Function<Integer, Apple> f) {
List<Apple> result = new ArrayList<>();
for(Integer i : list) {
result.add(f.apply(i));
}
return result;
}Apple<String color, Integer weight)처럼 두 인수를 갖는 생성자는 BiFunction 인터페이스와 같은 시그니처를 가진다.
BiFunction<Color, Integer, Apple> c3 = Apple::new;
Apple a3 = c3.apply(GREEN, 110);이 코드는 다음과 같다.
BiFunction<String, Integer, Apple> c3 =
(color, weight) -> new Apple(color, weight);
Apple a3 = c3.apply(GREEN, 110);
인스턴스화하지 않고도 생성자에 접근할 수 있는 기능을 다양한 상황에 응용할 수 있다. 예를 들어 Map으로 생성자와 문자열값을 관련시키고 String과 Integer가 주어졌을 때 다양한 무게를 갖는 여러 종류의 과일을 만드는 giveMeFruit라는 메서드를 만들 수 있다.
static Map<String, Function<Integer, Fruit>> map = new HashMap<>();
static {
map.put("apple", Apple::new);
map.put("orange", Orange::new);
//...
}
public static Fruit giveMeFruit(String fruit, Integer weight) {
return map.get(fruit.toLowerCase()).apply(weight);
}람다, 메서드 참조 활용하기
1단계 : 코드 전달
어떻게 sort 메서드에 정렬 전략을 전달할 수 있을까?
sort 메서드는 다음과 같은 시그니처를 갖는다.
void sort(Comparator<? super E> c)객체 안에 동작을 포함시키는 방식으로 다양한 전략을 전달할 수 있다. 즉, 'sort의 동작은 파라미터화되었다'라고 말할 수 있다. sort에 전달된 정렬 전략에 따라 sort의 동작이 달라질 것이다.
public class AppleComparator implements Comparator<Apple> {
public int compare(Apple a1, Apple a2) {
return a1.getWeight().compareTo(a2.getWeight());
}
}
inventory.sort(neew AppleComparator());2단계 : 익명 클래스 사용
한 번만 사용할 Comparator를 구현하는 것보다 익명 클래스를 이용하는 것이 좋다.
inventory.sort(new Comparator<Apple>() {
public int compare(Apple a1, Apple a2) {
return a1.getWeight().compareTo(a2.getWeight());
}
});3단계 : 람다 표현식 사용
추상 메서드의 시그니처(함수 디스크립터)는 람다 표현식의 시그니처를 정의한다.
Comparator의 함수 디스크립터는 (T,T) -> int다. 우리는 사과를 사용할 것이므로 (Apple,Apple) -> int로 표현할 수 있다.
inventory.sort(Apple a1, Apple a2) ->
a1.getWeight().compareTo(a2.getWeight())
);
이를 줄이면 다음과 같다.
inventory.sort((a1, a2) -> a1.getWeight().compareTo(a2.getWeight()));
Comparator는 Comparable 키를 추출해서 Comparator 객체로 만드는 Function 함수를 인수로 받는 정적 메서드 comparing을 포함한다. 이를 사용하여 다음처럼 나타낼 수 있다.
Comparator<Apple> c = Comparator.comparing((Apple a) -> a.getWeight());
다음처럼 간소화할 수 있다.
import static java.util.Comparator.comparing;
inventory.sort(comparing(apple -> apple.getWeight()));4단계 : 메서드 참조 사용
메서드 참조를 이용해서 코드를 조금 더 간소화할 수 있다.
inventory.sort(comparing(Apple::getWeight));
이로써 코드 자체로 'Apple을 weight별로 비교해서 inventory를 sort하라'는 의미를 전달할 수 있다.
람다 표현식을 조합할 수 있는 유용한 메서드
간단한 여러 개의 람다 표현식을 조합해서 복작ㅂ한 람다 표현식을 만들 수 있다. 두 프레디케이트를 조합해서 두 프레디케이트의 or 연산을 수행하는 커다란 프레디케이트를 만들 수 있다. 또한 한 함수의 결과가 다른 함수의 입력이 되도록 두 함수를 조합할 수 있다. 함수형 인터페이스에서 디폴트 메서드를 제공하기에 이런 일이 가능하다.
Comparator 조합
Comparator.comparing을 이용해서 비교에 사용할 키를 추출하는 Function 기반의 Comparator를 반환할 수 있다.
Comparator<Apple> c = Comparator.comparing(Apple::getWeight);
역정렬
reverse라는 디폴트 메서드를 사용하여 역정렬할 수 있다.
inventory.sort(comparing(Apple::getWeight).reversed()); //무게 내림차순 정렬
Comparator 연결
무게가 같은 두 사과가 존재한다면 어떻게 해야 할까? 예를 들어 무게가 같다면 원산지 국가별로 사과를 정렬할 수 있다. thenComparing 메서드로 두 번째 비교자를 만들 수 있다. thenComparing은 함수를 인수로 받아 첫 번째 비교자를 이용해서 두 객체가 같다고 판단되면 두 번째 비교자에 객체를 전달한다.
inventory.sort(comparing(Apple::getWeight)
.reversed()
.thenComparing(Apple::getCountry));Predicate 조합
Predicate 인터페이스는 복잡한 프레디케이트를 만들 수 있도록 negate, and, or 세 가지 메서드를 제공한다. 예를 들어 '빨간색이 아닌 사과'처럼 특정 프레디케이트를 반전시킬 때 negate 메서드를 사용할 수 있다.
Predicate<Apple> notRedApple = redApple.negate();
and 메서드를 이용해서 빨간색이면서 무거운 사과를 선택하도록 두 람다를 조합할 수 있다.
Predicate<Apple> redAndHeavyApple =
redApple.and(apple -> apple.getWeight() > 150);
or을 이용해서 '빨간색이면서 무거운(150그램 이상) 사과 또는 그냥 녹색 사과' 등 다양한 조건을 만들 수 있다.
Predicate<Apple> redAndHeavyAppleOrGreen =
readApple.and(apple -> apple.getWeight() > 150)
.or(apple -> GREEN.equals(a.getColor()));Function 조합
Function 인터페이스는 Function 인스턴스를 반환하는 andThen, compose 두 가지 디폴트 메서드를 제공한다.
andThen 메서드는 주어진 함수를 먼저 적용한 결과를 다른 함수의 입력으로 전달하는 함수를 반환한다.
Function<Integer, Integer> f =x -> x + 1;
Function<Integer, Integer> g = x -> x + 2;
Function<Integer, Integer> h = f.compose(g);
int result = h.apply(1); //4를 반환
compose 메서드는 인수로 주어진 함수를 먼저 실행한 다음에 그 결과를 외부 함수의 인수로 제공한다.
Function<Integer, Integer> f =x -> x + 1;
Function<Integer, Integer> g = x -> x * 2;
Function<Integer, Integer> h = f.compose(g);
int result = h.apply(1); //3을 반환
예시로 다음처럼 문자열로 구성된 편지 내용을 변환하는 다양한 유틸리티 메서드가 있다고 가정하자.
public class Letter {
public static String addHeader(String text) {
return "From Prao, Ugirin and KYH: " + text;
}
public static String addFooter(String text) {
return text + " Kind regards";
}
public static String checkSpelling(String text) {
return text.replaceAll("labda", "lambda");
}
}
여기 유틸리티 메서드를 조합해서 다양한 변환 파이프라인을 만들 수 있다. 다음과 같이 헤더를 추가하고 철자 검사를 하고 마지막에 푸터를 추가할 수 있다.
Function<String, String> addHeader = Letter::addHeader;
Function<String, String> transformationPipeline =
addHeader.andThen(Letter::checkSpelling)
.andThen(Letter::addFooter);
또는 철자 검사를 빼고 헤더와 푸터만 추가하는 파이프라인도 만들 수 있다.
Function<String, String> addHeader = Letter::addHeader;
Function<String, String> transformationPipeline =
addHeader.andThen(Letter::addFooter);'Java > 모던 자바 인 액션' 카테고리의 다른 글
| [모던 자바 인 액션] 동적 파라미터화 (0) | 2023.11.04 |
|---|---|
| [모던 자바 인 액션] 자바의 변화(8 ~ 11) (1) | 2023.10.31 |
