
반응형
서로소 집합(Disjoint-sets)
상호 배타 집합
- 중복 포함된 원소가 없는 집합 → 교집합이 없음
- 각 집합은 대표자를 통해 구분
상호 배타 집합 표현 방법
- 연결 리스트
- 트리
- 연결리스트
- 배열
상호 배타 집합 연산
- Make-Set(x) : 단위집합을 만드는 연산 (초기화 함수)
- Find-Set(x) : 어떤 한 element가 주어졌을 때, 그 element의 대표자를 구하는 연산
- Union(x, y) : 두 구성요소가 주어지고, 그 두 구성요소의 각 상호배타 집합을 합치는 연산
Make-Set / Union / Find-Set 연산
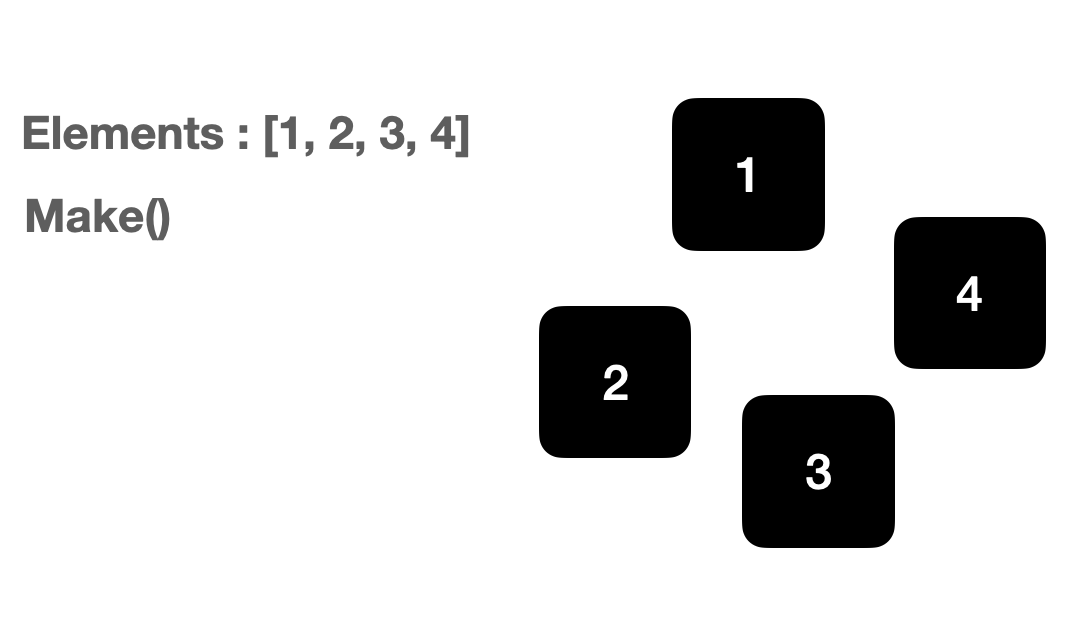

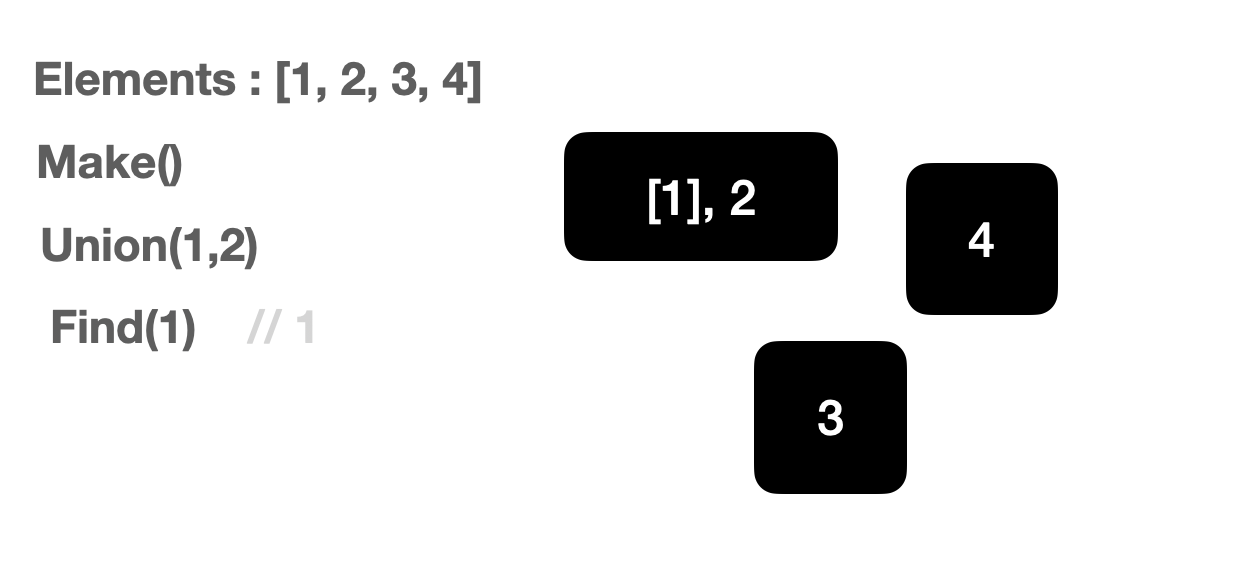
상호 배타 집합 표현 - 연결리스트
- 같은 집합의 원소들은 하나의 연결리스트로 관리
- 연결리스트의 맨 앞의 원소를 집합의 대표자로 결정
- 각 원소는 집합의 대표원소를 가리키는 링크를 갖는다.

- 대표자 노드는 항상 head에 위치
- 추가되는 노드들은 tail에 추가
- 대표자 노드가 아닌 값은 모두 대표자 값에 링크를 한개씩 두어서 대표자 노드를 가리킬 수 있게 함
class Node {
int data;
Node next;
Node linkToRep;
}https://jiwoochoi.tistory.com/212
Disjoint-set & Union-Find : 유니온 파인드
Union-Find 서로소, 상호배타 집합이란 서로 중복 표현된 원소가 없는 집합을 의미합니다. 이런 집합을 표현하기 위해서 "대표자" 라는 개념이 도입되는데, 이 대표자를 기준으로 각 집합을 구분할
jiwoochoi.tistory.com
상호 배타 집합 표현 - 트리

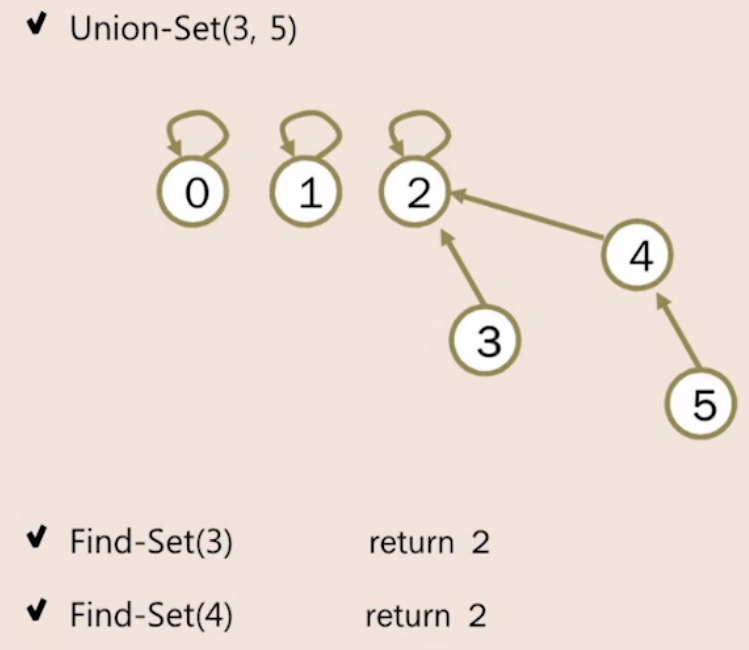
Make-Set(x) { # 노드 x를 유일한 원소로 하는 집합을 만든다.
p[x] ← x;
}
Union(x, y) { # 노드 x가 속한 집합과 노드 y가 속한 집합을 합친다
p[Find-Set(y)] ← Find-Set(x);
}
Find-Set(x) { # 노드 x가 속한 집합을 알아낸다. 노드 x가 속한 트리의 루트 노드를 리턴한다.
if (x = p[x]) : return x;
else : return Find-Set(p[x]);
}
상호 배타 집합 연산의 효율을 높이는 방법
알고리즘 : 집합의 처리
상호배타적 집합(disijiont set)만을 대상으로 한다. 즉 교집합 연산은 다루지 않는다.Mask-Set(x) : 원소 x로만 이루어진 집합을 생성한다.Find-Set(x) : 원소 x가 속한 집합을 알아낸다.Union(x, y) : 원소 x가
velog.io
Rank를 이용한 Union
- 각 노드는 자신을 루트로 하는 subtree의 높이를 랭크(rank)라는 이름으로 저장
- 두 집합을 Union할 때 rank가 낮은 집합을 높은 집합에 붙임
랭크가 변하지 않는 예시
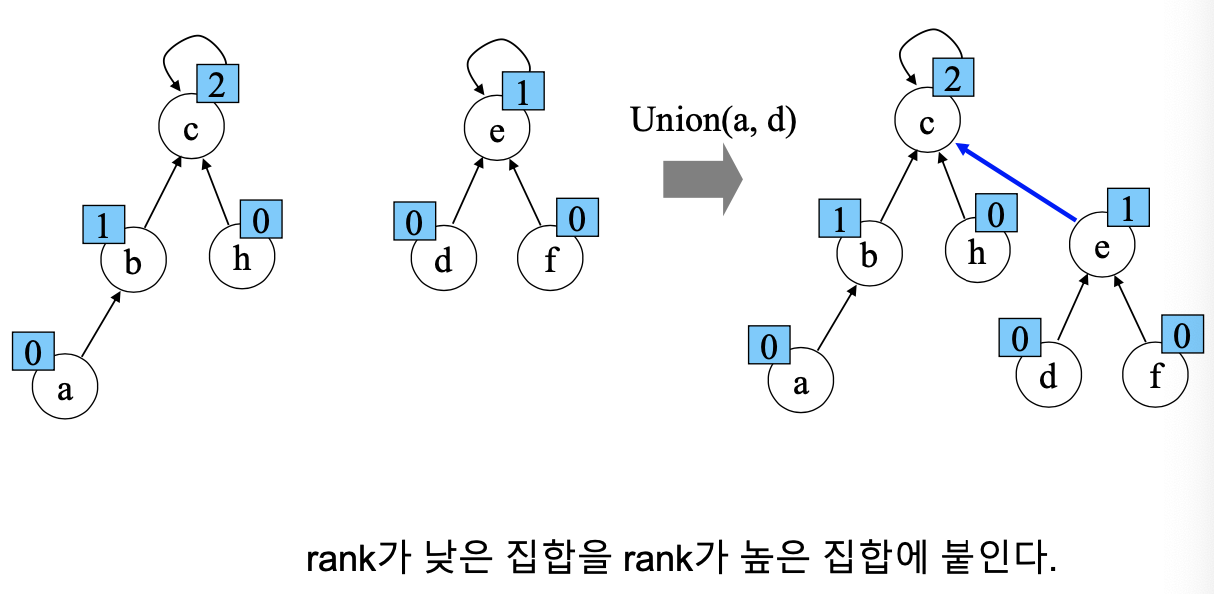
랭크가 변하는 예시

Path Compression
- Find-Set을 행하는 과정에서 만나는 모든 노드들이 직접 대표를 가리키도록 수정

- d,f는 아직 호출되지 않았기에 e 밑에 존재, 호출되면 c 밑으로 경로 압축
Make-Set() 연산
- 유일한 멤버 x를 포함하는 새로운 집합을 생성하는 연산
- 반복문을 이용하여 간소화
p[x] : 노드 x의 부모 저장
rank[x] : 루트 노드가 x인 트리의 랭크 값 저장
Make-Set(x)
p[x] ← x
rank[x] ← 0
Find-Set() 연산
- Find-Set(x) : x를 포함하는 집합을 찾는 연산
- 특정 노드에서 루트 노드까지의 경로를 찾아 가면서 노드 부모의 정보를 갱신
Find-Set(x)
IF x != p[x] : // x가 루트가 아닌 경우
p[x] ← Find-Set(p[x])
RETURN p[x]
Union 연산
- Union(x,y) : x와 y를 포함한느 두 집합을 합하는 연산
Union(x, y) // x, y는 대표자, rank는 트리의 높이
IF rank[x] > rank[y] : // x의 랭크가 높으면 x 밑으로 y가 들어간다
p[y] ← x
ELSE // 그 외에는 y의 밑으로 x가 들어간다
p[x] ← y
IF rank[x] == rank[y] : // 둘이 똑같다면 rank[y]의 높이를 1 증가시킨다
rank[y]++
MST(최소 비용 신장 트리; Minimum Spanning Tree)
신장 트리
- 그래프의 모든 정점과 간선의 부분 집합으로 구성되는 트리
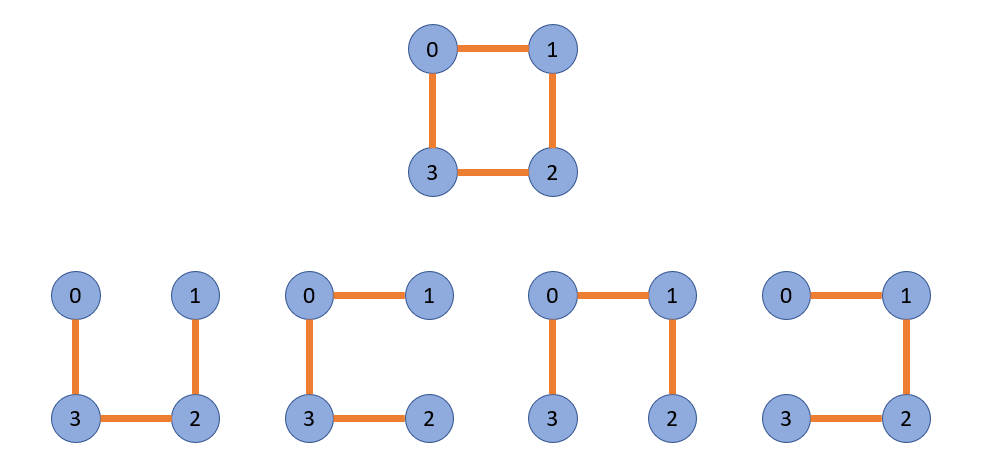
최소 신장 트리
- 신장 트리 중에서 사용된 간선들의 가중치 합이 최소인 트리
- 무방향 가중치 그래프
- N개의 정점을 가지는 그래프에 대해 반드시 (N-1)개의 간선을 사용
- 사이클을 포함 X
사용하는 이유
- 도로망, 통신망, 유통망 등등 여러 분야에서 비용을 최소로 해야 이익을 볼 수 있다.
- 대표적인 알고리즘으로 크루스칼, 프림이 있음(그리디 알고리즘 중 하나)
크루스칼 알고리즘(KRUSKAL)
동작 과정
- 최초 모든 간선을 가중치에 따라 오름차순으로 정렬
- 가중치가 가장 낮은 간선부터 선택하면서 트리를 증가시킴
→ 사이클이 존재하면 다음으로 가중치가 낮은 간선 선택 - N - 1개의 간선이 선택될 때까지 2번 과정 반복
1) 그래프 간선을 가중치 오름차순 정렬

2) a - b부터 선택
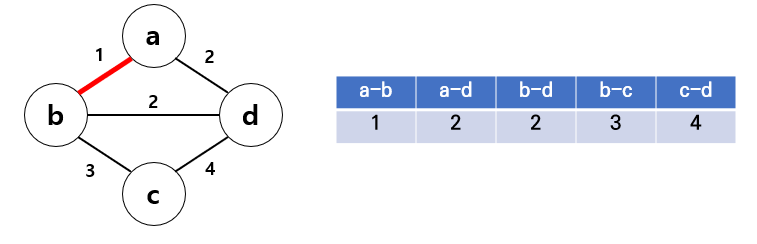
3) a - d 선택
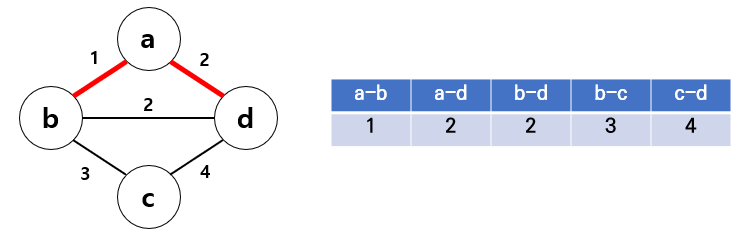
4) b - d를 선택하면 a - b - d 사이클이 형성되므로 선택 x

5) b - c 선택. 선택된 간선의 갯수가 정점의 갯수 - 1이 되면 종료

사이클 판단하기 - Union & Find 활용
https://chanhuiseok.github.io/posts/algo-33/
알고리즘 - 크루스칼 알고리즘(Kruskal Algorithm), 최소 신장 트리(MST)
##
chanhuiseok.github.io
크루스칼 알고리즘 의사코드
MST - KRUSKAL(G)
A ← 0 // 0 : 공집합
FOR v in G.V // G.V : 그래프의 정점 집합
Make-Set(v)
G.E에 포함된 간선들의 가중치 w에 의해 정렬 // G.E : 그래프의 간선 집합
FOR 가중치가 가장 낮은 간선 (u, v) ∈ G.E 선택(n-1개)
IF Find-Set(u) != Find-Set(v)
A ← A ∪ {(u, v)}
Union(u, v);
RETURN A
반응형
'TIL' 카테고리의 다른 글
| [TIL-53/240401] 위상 정렬 (0) | 2024.04.01 |
|---|---|
| [TIL-52/240328] 프림(Prim) 알고리즘 (0) | 2024.03.29 |
| [TIL-50/240322] JDBC (0) | 2024.03.23 |
| [TIL-49/240321] Join & SubQuery & Modeling (0) | 2024.03.22 |
| [TIL-48/240320] DDL & DML (0) | 2024.03.21 |
