TIL
[TIL-49/240321] Join & SubQuery & Modeling
prao
2024. 3. 22. 00:10
반응형
조인(Join)
- 두 개 이상의 테이블에서 행을 결합하는 방법
- 일반적으로 조인조건은 PK(Primary Key) 및 FK(Foregin Key)로 구성
- PK 및 FK 관계가 없더라도 논리적인 연관만 있으면 JOIN 가능
- 내부 조인 (INNER JOIN)
- 두 테이블의 교집합을 반환. 조인 조건을 충족하는 행만 반환
- 동등 조인(Equi-join)이라고도 함
- N개의 테이블 조인 시 N-1개의 조인 조건 필요
- 외부 조인 (OUTER JOIN): 하나의 테이블에는 존재하지만 다른 테이블에는 존재하지 않는 행도 포함하여 결과를 반환
- LEFT OUTER JOIN: 첫 번째 (왼쪽) 테이블의 모든 행과 일치하는 오른쪽 테이블의 행을 반환
- RIGHT OUTER JOIN: 두 번째 (오른쪽) 테이블의 모든 행과 일치하는 왼쪽 테이블의 행을 반환
- FULL OUTER JOIN: 양쪽 테이블의 모든 행을 반환
MySQL에서는 FULL OUTER JOIN을 직접 지원 X, 하지만 UNION이나 UNION ALL을 사용하여 비슷한 결과를 얻을 수 있음
- 자연 조인 (NATURAL JOIN): 두 테이블에서 이름과 자료형이 같은 모든 열을 기준으로 조인을 수행
- 교차 조인 (CROSS JOIN): 두 테이블의 모든 가능한 조합을 반환
조인시 주의사항
- 조인 조건 누락
- 조인 조건을 누락하면 두 테이블의 모든 가능한 조합이 결과로 반환.
- 이를 카테시안 곱이라고 하며, 의도하지 않은 큰 결과 세트를 생성할 수 있음
- NULL 처리
- 외부 조인을 사용할 때, 일치하는 행이 없는 경우 NULL 값이 결과에 포함
- 따라서, 이러한 NULL 값을 처리하는 로직이 필요할 수 있음
- 성능 이슈
- 큰 테이블을 조인할 때는 성능이 크게 저하될 수 있음
- 이를 최적화하기 위한 적절한 인덱스 설정이 필요
쿼리 속도를 높이는 방법
- 인덱스 사용: 조인 조건에 사용되는 열에 인덱스를 생성시 인덱스를 사용하여 조인을 빠르게 수행 가능
- 필요한 열만 선택: SELECT * 대신 필요한 열만 명시적으로 선택시 불필요한 데이터를 처리하는 시간을 줄일 수 있음
- WHERE 절 사용: 가능한 한 조인 전에 WHERE 절을 사용하여 필터링을 수행시 조인해야 하는 행의 수를 줄일 수 있음
- 조인 순서 최적화: MySQL은 자동으로 최적의 조인 순서를 결정, 경우에 따라서는 STRAIGHT_JOIN을 사용하여 조인 순서를 명시적으로 지정하는 것이 유리함
예시
Employees 테이블
| EmployeeID | EmployeeName | DepartmentID |
| 1 | John | 1 |
| 2 | Jane | 2 |
| 3 | Mark | 1 |
| 4 | Emily | 3 |
Departments 테이블
| DepartmentID | DepartmentName |
| 1 | Sales |
| 2 | Marketing |
| 3 | HR |
| 4 | IT |
INNER JOIN (내부 조인)
SELECT Employees.EmployeeID, Employees.EmployeeName, Employees.DepartmentID, Departments.DepartmentName
FROM Employees
INNER JOIN Departments ON Employees.DepartmentID = Departments.DepartmentID;
| EmployeeID | EmployeeName | DepartmentID | DepartmentName |
| 1 | John | 1 | Sales |
| 2 | Jane | 2 | Marketing |
| 3 | Mark | 1 | Sales |
| 4 | Emily | 3 | HR |
- INNER JOIN은 두 테이블 간의 일치하는 값을 기준으로 결과를 반환
- 위의 예제에서는 "Employees" 테이블과 "Departments" 테이블을 DepartmentID 열을 기준으로 INNER JOIN하여 일치하는 값을 가져옴
OUTER JOIN (외부 조인)
SELECT Employees.EmployeeID, Employees.EmployeeName, Departments.DepartmentID, Departments.DepartmentName
FROM Employees
LEFT OUTER JOIN Departments ON Employees.DepartmentID = Departments.DepartmentID;
| EmployeeID | EmployeeName | DepartmentID | DepartmentName |
| 3 | Mark | 1 | Sales |
| 1 | John | 1 | Sales |
| 2 | Jane | 2 | Marketing |
| 4 | Emily | 3 | HR |
| NULL | NULL | 4 | IT |
- OUTER JOIN은 두 테이블 간의 일치하지 않는 값을 포함하여 결과를 반환
- 위의 예제에서는 "Employees" 테이블과 "Departments" 테이블을 DepartmentID 열을 기준으로 LEFT OUTER JOIN하여 모든 직원과 일치하는 부서를 가져옴
- 오른쪽에는 "Employees" 테이블에는 없는 부서인 IT 부서를 나타내기 위해 NULL 값을 포함
NATURAL JOIN (자연 조인)
SELECT EmployeeID, EmployeeName, DepartmentID
FROM Employees
NATURAL JOIN Departments;
| EmployeeID | EmployeeName | DepartmentID |
| 1 | John | 1 |
| 2 | Jane | 2 |
| 3 | Mark | 1 |
| 4 | Emily | 3 |
- NATURAL JOIN은 두 테이블 간의 동일한 열 이름을 기준으로 일치하는 값을 가져옴
- 위의 예제에서는 "Employees" 테이블과 "Departments" 테이블을 DepartmentID 열을 기준으로 NATURAL JOIN하여 일치하는 값을 가져옴
- 결과에는 EmployeeID, EmployeeName, DepartmentID 열만 포함
CROSS JOIN (교차 조인)
SELECT Employees.EmployeeID, Employees.EmployeeName, Departments.DepartmentID, Departments.DepartmentName
FROM Employees
CROSS JOIN Departments
ORDER BY Employees.EmployeeID;
| EmployeeID | EmployeeName | DepartmentID | DepartmentName |
| 1 | John | 1 | Sales |
| 1 | John | 2 | Marketing |
| 1 | John | 3 | HR |
| 1 | John | 4 | IT |
| 2 | Jane | 1 | Sales |
| 2 | Jane | 2 | Marketing |
| 2 | Jane | 3 | HR |
| 2 | Jane | 4 | IT |
| 3 | Mark | 1 | Sales |
| 3 | Mark | 2 | Marketing |
| 3 | Mark | 3 | HR |
| 3 | Mark | 4 | IT |
| 4 | Emily | 1 | Sales |
| 4 | Emily | 2 | Marketing |
| 4 | Emily | 3 | HR |
| 4 | Emily | 4 | IT |
- CROSS JOIN은 두 테이블의 모든 가능한 조합을 반환
- 위의 예제에서는 "Employees" 테이블과 "Departments" 테이블을 CROSS JOIN하여 모든 직원과 모든 부서의 조합을 가져옴
서브 쿼리(SubQuery)
서브 쿼리(SubQuery)란?
- 하나의 SQL문 안에 포함되어 있는 SQL문
- 서브 쿼리를 포함하는 SQL을 외부 쿼리(outer query) 또는 메인 쿼리라고 부르며, 서브 쿼리는 내부 쿼리(inner query)라고도 부름
서브 쿼리의 종류
- 중첩 서브 쿼리(Nested SubQuery) - WHERE 절에 작성하는 서브 쿼리
- 단일-행, 다중-행, 다중-열
- 인라인 뷰(Inline-view) - FROM 절에 작성하는 서브 쿼리
- 스칼라 서브 쿼리(Scalar SubQuery) - SELECT 문에 작성하는 서브 쿼리
서브 쿼리를 포함할 수 있는 SQL문
- SELECT, FROM, WHERE, HAVING, ORDER BY
- INSERT문의 VALUES
- UPDATE문의 SET
서브 쿼리의 사용시 주의사항
- 서브 쿼리는 반드시 ()로 감싸서 사용
- 서브 쿼리는 단일 행 또는 다중 행 비교 연산자와 함께 사용 가능
- 단일 행 비교 연산자는 서브 쿼리 결과가 1건 이하이어야 함
- 복수 행 비교 연산자는 결과 건수와 상관없음
서브 쿼리의 필요성
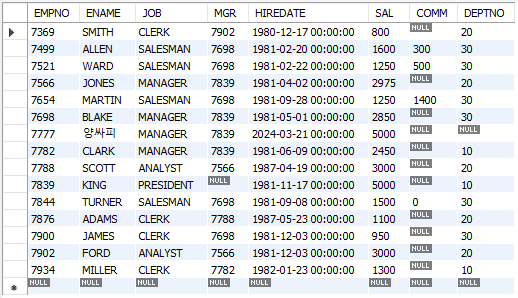

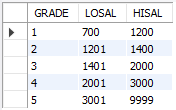
중첩 서브 쿼리(Nested SubQuery), 단일 행
사번이 7788인 사원의 부서 이름을 조회
- 서브쿼리 x
SELECT d.dname
FROM emp e, dept d
WHERE e.deptno = d.deptno
AND e.empno = 7788;- 서브쿼리 o
SELECT dname
FROM dept
WHERE deptno = (SELECT deptno
FROM emp
WHERE empno = 7788);서브쿼리 사용 이유
dname을 조회하기 위해 INNER JOIN 수행 → 쿼리 복잡해질 시 카테시안곱으로 인해 속도 느려짐 → Sub Query로 JOIN 없이 조회 가능
매니저 이름이 'KING'인 사원의 사번, 이름, 부서번호, 업무 조회
SELECT empno, ename, deptno, job
FROM emp
WHERE mgr = (SELECT empno
FROM emp
WHERE ename = 'KING');
7566 사원보다 급여를 많이 받는 사원의 이름, 급여를 조회
SELECT ename, sal
FROM emp
WHERE sal > (SELECT sal
FROM emp
WHERE empno = 7566);
20번 부서의 평균 급여가 많은 사원의 사번, 이름, 업무, 급여 조회
SELECT empno, ename, job, sal
FROM emp
WHERE sal > (SELECT AVG(sal)
FROM emp
WHERE deptno = 20);
업무가 'TURNER'와 같고, 사번이 7934인 직원보다 급여가 많은 사원의 사번, 이름, 업무를 조회
SELECT empno, ename, job
FROM emp
WHERE job = (SELECT job
FROM emp
WHERE ename = 'TURNER')
AND sal > (SELECT sal
FROM emp
WHERE empno = 7934);
서브 쿼리 - 중첩 서브 쿼리(Nested SubQuery), 다중 행
- 서브 쿼리 결과가 다중 행을 반환 : IN, ANY, ALL 연산자와 함께 사용
업무가 'SALESMAN'인 직원들 중 최소 한 명 이상보다 많은 급여를 받는 사원의 이름, 급여, 업무를 조회
SELECT ename, sal, job
FROM emp
WHERE sal > ANY (SELECT sal
FROM emp
WHERE job = 'SALESMAN');- > ANY : 최솟값보다 큼
- < ANY : 최댓값보다 작음
업무가 'SALESMAN'인 모든 직원보다 급여(커미션포함)를 많이 받는 사원의 이름, 급여, 업무, 입사일, 부서번호 조회
SELECT ename, sal, job, hiredate, deptno
FROM emp
WHERE sal > ALL (SELECT sal + IFNULL(comm, 0)
FROM emp
WHERE job = 'SALESMAN');직원이 최소 한명이라도 근무하는 부서의 부서번호, 부서이름, 위치
- DISTINCT 키워드를 이용해 중첩되는 행 제거
- in 다중행에 하나라도 일치하면 조회,= ANY와 같음
SELECT deptno, dname, loc
FROM dept
WHERE deptno IN (SELECT DISTINCT deptno
FROM emp);
-- ANY
SELECT deptno, dname, loc
FROM dept
WHERE deptno = ANY (SELECT DISTINCT deptno
FROM emp);
서브 쿼리 - 중첩 서브 쿼리(Nested SubQuery), 다중 열
- 서브 쿼리의 결과값이 두 개 이상의 column을 반환하는 서브 쿼리
- PK가 복합키(Composite Key)이거나, 여러 column의 값을 한꺼번에 비교해야 할 경우 사용
- 행 생성자(row constructor)를 이용하여 다중 열 서브 쿼리를 비교
- 아래 두 SQL은 의미상 동일하고 동일한 방식으로 처리됨
SELECT * FROM t1 WHERE (column1, column2) = (1,1);
SELECT * FROM t1 WHERE column1 = 1 AND column2 = 1;- 결과가 다중 행일 경우 IN 연산자를 이용
SELECT column1, column2, column3
FROM t1
WHERE (column1, column2, column3)
IN (SELECT column1, column2, column3
FROM t2);
이름이 FORD인 사원과 매니저 및 부서가 같은 사원의 이름, 매니저번호, 부서번호 조회
SELECT ename, mgr, deptno
FROM emp
WHERE (mgr , deptno) = (SELECT mgr, deptno
FROM emp
WHERE ename = 'FORD')
AND ename <> 'FORD';
각 부서별 입사일이 가장 빠른 사원의 사번, 이름, 부서번호, 입사일 조회
SELECT empno, ename, deptno, hiredate
FROM emp
WHERE (deptno , hiredate) IN (SELECT deptno, MIN(hiredate)
FROM emp
GROUP BY deptno);
서브 쿼리 - 상호연관 서브 쿼리(Correlated SubQueries)
- 외부 쿼리에 있는 테이블에 대한 참조를 하는 서브 쿼리를 의미
- 예시
SELECT * FROM t1
WHERE column1 = ANY(SELECT column1
FROM t2
WHERE t2.column2 = t1.column2);- 서브 쿼리의 FROM에는 t1에 대한 선언이 존재하지 않음 → 서브 쿼리는 외부 쿼리(메인 쿼리)에서 t1 참조
- 테이블에서 행을 먼저 읽어서 각 행의 값을 관련된 데이터와 비교하는 방법 중 하나
- 기본 질의에서 고려된 각 후보행에 대해 서브 쿼리가 다른 결과를 반환해야 하는 경우 사용
- 서브 쿼리에서는 메인 쿼리의 컬럼명을 사용할 수 있으나, 메인 쿼리에서는 서브 쿼리의 컬럼명 사용 불가
소속 부서의 평균 급여보다 많은 급여를 받는 사원의 이름, 급여, 부서번호, 입사일, 업무 조회
SELECT ename, sal, deptno, hiredate, job
FROM emp e
WHERE sal > (SELECT AVG(sal)
FROM emp
WHERE deptno = e.deptno)
ORDER BY deptno;
서브 쿼리 - 인라인 뷰(Inline View)
- FROM절에서 사용되는 서브 쿼리
- 동적으로 생성된 테이블로 사용 가능
- 뷰와 같은 역할
SELECT ... FROM (subquery) [AS] tbl_name(col_list)...- 인라인 뷰는 SQL문이 실행될 때만 임시적으로 생성되는 뷰
→ 데이터베이스에 해당 정보가 저장 X → 동적 뷰(Dynamic View)라고도 부름
모든 사원의 평균 급여보다 적게 받는 사원들과 같은 부서에서 근무하는 사원의 사번, 이름, 급여, 부서번호 조회
SELECT e.empno, e.ename, e.sal, e.deptno
FROM emp e, (SELECT DISTINCT deptno
FROM emp
WHERE sal < (SELECT AVG(sal)
FROM emp)
) AS d
WHERE e.deptno = d.deptno;
모든 사원에 대하여 사원의 이름, 부서번호, 급여, 사원이 소속된 부서의 평균 급여를 조회(단, 이름 오름차순)
SELECT e.ename, e.deptno, e.sal, d.avgsal
FROM emp e, (SELECT deptno, AVG(sal) AS avgsal
FROM emp
GROUP BY deptno) d
WHERE e.deptno = d.deptno
ORDER BY e.ename;
서브 쿼리 - 스칼라 서브 쿼리(Scalar SubQuery)
- 하나의 행에서 하나의 컬럼 값만 반환하는 서브 쿼리
- 다음과 같은 경우에 사용 가능
- GROUP BY를 제외한 SELECT의 모든 절
- INSERT문의 VALUES
- 조건 및 표현식 부분
- UPDATE문의 SET 또는 WHERE절에서 연산자 목록
사원의 이름, 부서번호, 급여, 소속부서의 평균 급여를 조회
SELECT ename, deptno, sal, (SELECT AVG(sal)
FROM emp
WHERE deptno = e.deptno) AS avgsal
FROM emp e;
부서번호가 10인 부서의 총 급여, 20인 부서의 평균 급여, 30인 부서의 최고, 최저 급여
SELECT (SELECT SUM(sal)
FROM emp
WHERE deptno = 10) AS SUM10,
(SELECT AVG(sal)
FROM emp
WHERE deptno = 20) AS AVG20,
(SELECT MAX(sal)
FROM emp
WHERE deptno = 30) AS MAX30,
(SELECT MIN(sal)
FROM emp
WHERE deptno = 30) AS MIN30
FROM dual;
모든 사원의 번호, 이름, 부서번호, 입사일을 조회(단, 부서이름기준으로 내림차순)
UPDATE emp SET deptno = 40
WHERE empno = 4168;
SELECT empno, ename, deptno, hiredate
FROM emp e
ORDER BY (SELECT dname
FROM dept
WHERE deptno = e.deptno) DESC;
emp table을 emp_copy라는 이름으로 복사(컬럼 이름 동일)
CREATE TABLE emp_copy
(SELECT * FROM emp);emp table 구조만 emp_blank라는 이름으로 복사하여 생성
CREATE TABLE emp_blank
(SELECT * FROM emp WHERE 1 = 0);부서 번호가 30인 사원의 모든 정보를 emp_blank에 INSERT
INSERT INTO emp_blank
(SELECT * FROM emp WHERE deptno = 30);데이터베이스 모델링(Database Modeling)
현실세계에서 데이터베이스까지 만들어지는 과정
개념적 데이터 모델 → 논리적 데이터 모델 → 물리적 데이터 모델

| 개념적 데이터 모델링 | 추상화 수준이 높고 업무중심적이고 포괄적인 수준의 모델링 진행. 전사적 데이터 모델링, EA 수립시 많이 사용 |
| 논리적 데이터 모델링 | 시스템으로 구축하고자 하는 업무에 대해 Key, 속성, 관계 등을 정확하게 표현, 재사용성이 높음 |
| 물리적 데이터 모델링 | 실제로 데이터베이스에 이식할 수 있도록 성능, 저장 등 물리적인 성격을 고려하여 설계 |
ERD 기호
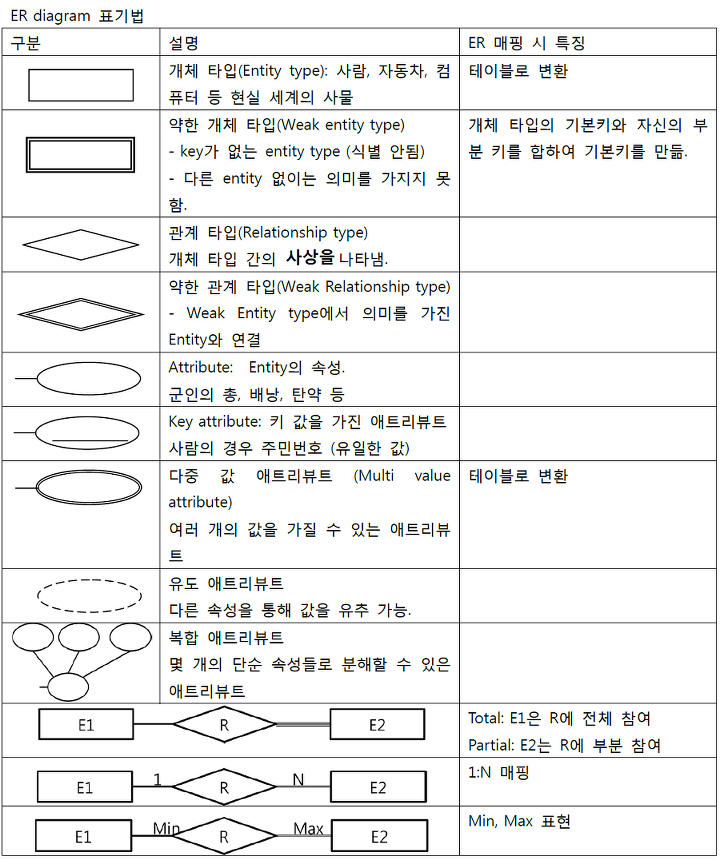

개념적 데이터베이스 모델링
- 개체(Entity)
- 사용자와 관계가 있는 주요 객체(데이터로 관리되어야 하는 것)
- Entity 찾는 법
- 영속적으로 존재하는 것
- 새로 식별이 가능한 데이터 요소를 가짐
- Entity는 Attribute를 가져야 함
- 속성(Attribute)
- 저장할 필요가 있는 실체에 관한 정보
- 개체(Entity)의 성질, 분류, 수량, 상태, 특성 등을 나타내는 세부사항
- 개체에 포함되는 속성의 숫자는 10개 내외로 하는 것이 바람직함
- 최종 DB 모델링 단계를 통해 테이블의 컬럼으로 활용
개념적 데이터베이스 모델링
식별자: 한 개체(Entity) 내에서 인스턴스를 구분할 수 있는 단일 속성 또는 속성 그룹
후보키(Candidate Key): 개체 내에서 각각의 인스턴스를 구분할 수 있는 속성(기본키 될 수 있음)
기본키(Primary Key): 개체(Entity)에서 각 인스턴스를 유일하게 식별하는데 적합한 Key
대체키(Alternate Key): 후보키 중에서 기본키로 선정되지 않은 Key
복합키(Composite Key): 하나의 속성으로 기본키가 될 수 없는 경우 둘 이상의 컬럼을 묶어서 식별자로 정의
대리키(Surrogate Key): 식별자가 너무 길거나 여러 개의 속성으로 구성되어 있는 경우 인위적으로 추가
- 관계(Relationship): 두 Entity 간의 업무적인 연관성 또는 관련 사실
- 각 Entity 간에 특정한 존재여부 결정
- 현재의 관계 뿐만 아니라 장래에 사용될 경우도 고려
ERD 관계를 설정하는 순서
- 관계가 있는 두 실체를 실선(점선)으로 연결하고 관계 부여
- 관계 차수를 표현
- 선택성을 표시
논리적 데이터베이스 모델링
기본키(Primary Key)
- 후보키 중에서 선택한 주 키
- 널(Null)의 값을 가질 수 없다(Not Null).
- 동일한 값이 중복해서 저장될 수 없다(Unique).
참조키, 이웃키(Foreign Key)
- 관계를 맺는 두 엔티티에서 서로 참조하는 릴레이션의 attribute로 지정되는 키
정규화
일반적인 겨우 1차 정규화에서 3차 정규화까지만 이뤄진다.

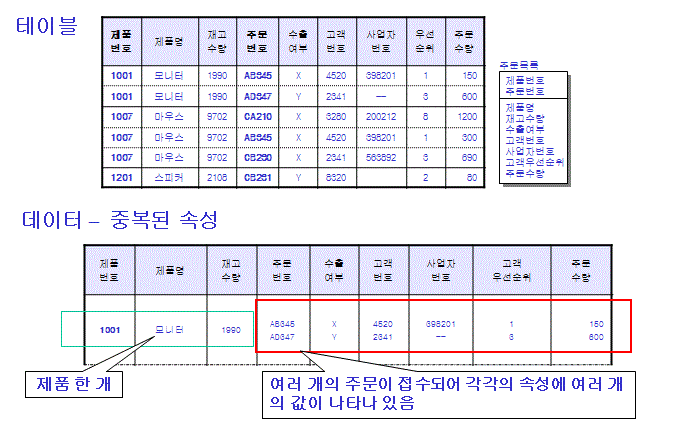
1차 정규화
- 테이블 하나의 컬럼에는 여러 개의 데이터 값이 중복되어 나타나지 않아야 함
- 모든 엔티티타입의 속성은 하나의 속성값만을 가지고 있어야 하며 반복되는 속성의 집단은 별도의 엔티티타입으로 분리


2차 정규화
- 수출여부, 고객번호, 사업자번호, 우선순위는 '제품번호+주문번호'로 구성된 주 식별자에 의해 종속적이지 않고 단지 주문번호에 의해 종속적인 관계를 가지고 있음
- 주문수량은 제품에 대해서 주문한 양이 되므로 '제품번호+주문번호'에 종속적임

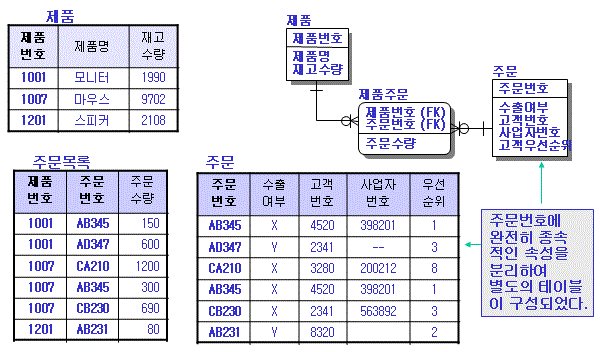
3차 정규화
- 3차 정규화의 대상이 되는 속성들을 이전종속(Transitive Dependence) 관계속성이라 함
- 주식별자에 의해 종속적인 속성 중에서 다시 다른 속성을 결정하는 결정자가 존재하여 다른 속성이 이 결정자 속성에 종속적인 관계를 나타내는 관계


정규화(Normalization)의 목적
- 데이터베이스의 변경 시 이상 현상 제거
- 데이터베이스 구조 확장 시 재 디자인 최소화
- 사용자에게 데이터 모델을 더욱 의미있게 작성하도록 함
- 다양한 질의 지원
물리적 데이터베이스 모델링
- 논리적 데이터베이스 모델링 단계에서 얻어진 데이터베이스 스키마를 좀 더 효율적으로 구현하기 위한 작업
- DBMS 특성에 맞게 실제 데이터베이스 내의 개체들을 정의하는 단계
- Column의 domain 설정(int, varchar, date, ...)
- 데이터 사용량 분석과 업무 프로세스 분석을 통해서 보다 효율적인 데이터베이스가 될 수 있도록 효과적인 인덱스를 정의하고 상황에 따른 역정규화 작업 수행
- Index, Trigger, 역정규화
역정규화(Denormalization)
- 시스템 성능을 고려하여 기존 설계를 재구성하는 것
- 정규화에 위배되는 행위
- 테이블의 재구성
역정규화 방법
- 데이터 중복(컬럼 역정규화)
- 파생 컬럼 생성
- 테이블 분리
- 요약 테이블 생성
- 테이블 통합
반응형